한국의 AI 혁신을 세계에 알리다: 이탈리아 SIGIR 2025에서 공개된 메이크봇의 HybridRAG 프레임워크
한국의 Makebot이 HybridRAG 프레임워크로 어떤 AI 혁신을 이끄는가


한양대학교 연구원 전현아, SIGIR 2025에서 메이크봇의 HybridRAG 프레임워크 발표
Padua, Italy – 2025년 7월 17일
2025년 7월 17일, 저희는 세계 최고 수준의 정보 검색 학술대회인 SIGIR 2025에서 메이크봇의 최신 연구 성과인 AI 기반 문서 검색 기술을 발표하는 뜻깊은 기회를 가졌습니다. 이번 행사는 이탈리아의 역사적인 도시 파도바(Padua)에서 열렸으며, 전 세계 학계와 산업계의 전문가들이 한자리에 모여 검색 기술, 대규모 언어 모델(LLM), 추천 시스템 등 다양한 분야의 혁신을 공유하는 자리였습니다.
저희 논문 「HybridRAG: Pre-Generated Q&A 기반의 비정형 원문 처리용 실용적 LLM 챗봇 프레임워크」는 한양대학교 연구원 전현아가 발표를 맡았으며, 연구는 메이크봇 CEO인 김지웅이 총괄 및 주도하였습니다. 김지웅 대표는 본 시스템의 LLM 및 RAG 엔진을 설계하고, 관련 특허 출원까지 직접 수행하며 이번 프로젝트를 이끌었습니다.
🏛️ 지식의 도시 Padua에서

학술대회 장소로 이보다 더 적합한 곳이 있을까요? Padua는 이탈리아에서 가장 오래된 대학 도시 중 하나로, 르네상스의 고풍스러운 분위기와 학문적 열정이 어우러진 곳입니다. 발표를 준비하면서 좁은 골목길, 햇살 가득한 광장, 수백 년의 역사를 지닌 건물들이 주는 분위기 속에서 지적인 자극을 한껏 느낄 수 있었습니다.
🏢 행사 장소: Centro Congressi – Fiera di Padova



SIGIR 2025는 Fiera di Padova 내 Centro Congressi에서 개최되었습니다. 이 현대적인 컨벤션 센터는 연구자와 업계 관계자 모두에게 탁월한 시설을 제공하며, 행사장 내부는 다양한 대화와 토론으로 열기가 넘겼습니다. 알고리즘 이론부터 실제 AI 시스템 적용까지, 모든 코너에서 풍부한 지식 교류가 이어졌습니다.
🧠 Mantegna Hall 2 무대 위에서


저희 발표는 3층에 위치한 Mantegna Hall 2에서 진행되었습니다. HybridRAG에 대한 발표를 듣기 위해 많은 청중들이 자리를 가득 메웠고, 모두가 깊은 관심을 보이며 귀를 기울였습니다.
HybridRAG은 기존 Retrieval-Augmented Generation(RAG) 시스템의 한계를 극복하고자 개발된 실용적인 프레임워크로, 사전 생성된 Q&A 쌍을 활용하여 LLM과 함께 비정형 문서 위에서 더 빠르고 정확한 응답을 제공하는 구조입니다. 이 접근 방식은 확장성과 비용 효율성 측면에서도 강점을 가지며, 현재 한국 내 실제 서비스에 적용해 성능을 검증 중입니다.
🍝 점심과 함께한 네트워킹 – 이탈리아식 소통

발표가 끝난 후에는 여유로운 점심 시간을 통해 세계 각국의 연구자들과 교류할 수 있었습니다. 파스타와 에스프레소를 즐기며 유럽, 미국, 아시아 등 다양한 지역의 전문가들과 성능 평가 기준부터 다국어 환경에서의 LLM 적용까지 폭넓은 주제로 깊이 있는 대화를 나누었습니다.
📌 포스터 세션: HybridRAG을 가까이에서
이후 오후에는 포스터 발표 세션에 참여해 참석자들과 일대일로 소통할 수 있는 기회를 가졌습니다. 많은 분들이 저희 접근 방식의 실용성에 큰 관심을 보였으며, 특히 기존 RAG 모델 대비 성능 향상을 어떻게 검증했는지에 대해 깊은 질문이 이어졌습니다.
이번 연구는 김지웅 대표의 주도로 시작된 프로젝트로, 메이크봇이 단순한 이론적 모델을 넘어 실제 현장에서 바로 활용 가능한, 확장성 있는 AI 도구를 만드는 데 집중하고 있다는 철학을 잘 보여주는 사례이기에, 그 내용을 공유할 수 있어 더욱 뜻깊었습니다.
HybridRAG: 실전 문서 기반 질의응답의 난제를 해결하다
기존의 RAG 시스템은 PDF처럼 복잡한 레이아웃, 표, 다양한 콘텐츠 유형이 혼합된 비정형 문서를 처리할 때 근본적인 병목 현상을 겪습니다. 일반적인 방식은 잘 구조화된 텍스트를 전제로 문서를 검색하고 그때그때 답변을 생성하지만, 이는 특히 엔터프라이즈 환경에서 성능 저하와 높은 비용 문제를 유발합니다.
HybridRAG가 해결하는 핵심 문제들
느리고 비효율적인 실시간 처리
기존 RAG 시스템은 매 쿼리마다 전체 검색과 응답 생성을 수행하기 때문에 처리 속도가 느리고 연산 자원이 과도하게 소모됩니다. 특히 높은 트래픽 환경에서는 실시간 응답이 어려워집니다.
복잡한 문서 형식에 취약
일반적인 RAG은 단락 단위로 문서를 분할(chunking)하지만, PDF처럼 구조가 복잡하거나 표와 이미지가 포함된 문서는 이를 잘 처리하지 못합니다. 그 결과 재무 표나 중첩된 섹션, 도표 같은 요소를 놓치며 문맥이 단절되거나 핵심 정보를 누락하게 됩니다.
섹션 간 문맥 연결 부족
법률 문서나 기술 매뉴얼처럼 섹션 간 참조가 많은 문서에서는 맥락 유지가 매우 중요하지만, 기존 방식은 이 연결을 파악하지 못해 부정확하거나 왜곡된 답변이 생성될 수 있습니다.
규모 확장에 대한 어려움
문서가 많아질수록 벡터 검색 공간도 커지고, 이로 인해 검색 속도 저하와 비용 증가가 발생합니다. 특히 정밀한 문맥 이해가 중요한 도메인에서는 치명적인 한계로 작용합니다.
HybridRAG의 혁신적인 접근 방식
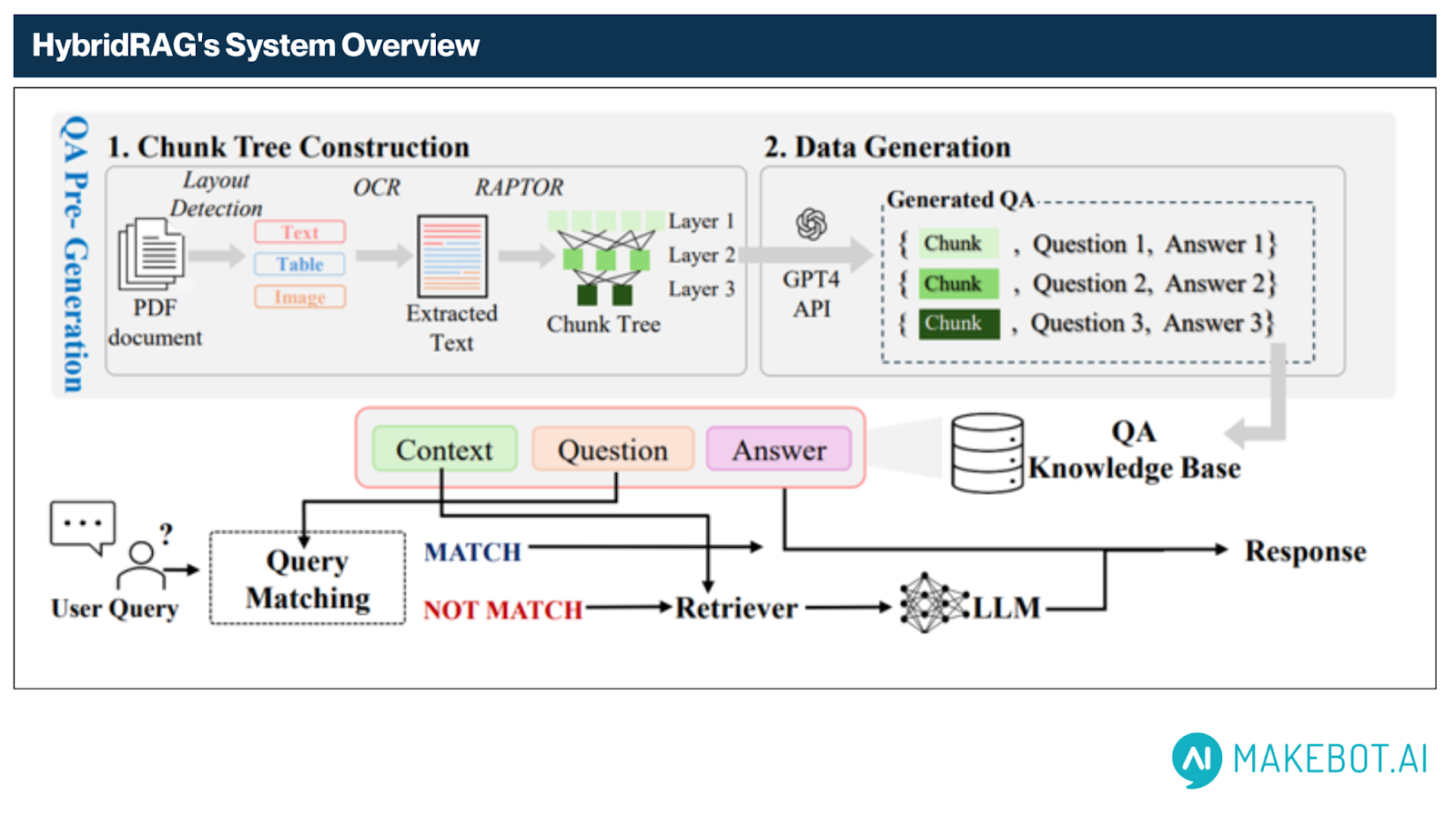
HybridRAG은 기존 RAG의 실시간 기반 아키텍처를 근본부터 재정의합니다. 실시간 생성이 아닌 오프라인 QA 사전 생성 방식을 채택하여, 도메인 특화 PDF 문서로부터 질의응답 지식 베이스를 구축합니다. 이후 실제 질의 시점에서는 임베딩 기반 의미 검색을 통해 빠르고 정확하게 응답합니다.
기존 RAG의 한계 vs HybridRAG의 강화점
전통적인 RAG 시스템은 문서 기반 질의응답에 여러 한계를 보입니다. 실시간 검색과 LLM 추론에 의존하기 때문에 응답 지연과 높은 운영 비용이 발생하며, 단락 단위 분할은 복잡한 문서 레이아웃(예: 재무표, 도면 등)에 적합하지 않아 문맥 단절을 유발합니다. 또한 일반적인 벡터 검색은 의미적으로 부정확한 내용을 포함하는 경우가 많아, 허위 응답(hallucination)이나 불완전한 결과를 낳을 수 있습니다.
HybridRAG은 이러한 문제를 아키텍처와 콘텐츠 처리 측면에서 모두 혁신적으로 개선했습니다. 대부분의 쿼리에 대해 실시간 LLM 호출 없이 처리할 수 있도록 오프라인 QA 사전 생성 방식을 도입했고, 다음과 같은 고도화된 파이프라인을 갖추고 있습니다:
- 레이아웃 기반 문서 분할 (MinerU 활용)
- RAPTOR에서 영감을 얻은 계층적 문서 구조 분석
- GPT-4o를 통한 시각 요소(도표, 그림 등) 해석
이로 인해 보다 정밀한 의미 표현과 구조화된 QA 매핑이 가능해졌습니다.
또한 HybridRAG은 표나 도표 등 시각적 데이터를 자연어로 해석해내는 도메인 특화 시각 추론 기능을 포함하고 있어, 재무, 행정 등 구조화된 시각 정보가 핵심인 분야에서도 높은 성능을 발휘합니다.
HybridRAG 작동 원리
HybridRAG은 두 단계로 구성된 파이프라인—오프라인 QA 사전 생성과 온라인 질의 매칭—을 기반으로 작동합니다. 이 구조는 복잡하고 비정형적인 문서(PDF 등)를 대상으로, 낮은 지연 시간과 높은 품질의 질의응답을 동시에 실현할 수 있도록 최적화되어 있습니다.
1. 오프라인 단계 – QA 사전 생성
이 단계에서는 원본 PDF 문서를 구조적으로 분석하고, LLM의 도움을 받아 의미 기반 QA 지식 베이스로 변환합니다. 전체 과정은 두 가지 주요 단계로 구성되며, 아래 다이어그램처럼 진행됩니다:
Chunk Tree Construction과 Data Generation입니다.
- 페이지당 약 15개의 QA 쌍을 생성하고, 200 토큰 크기의 RAPTOR 루트 노드처럼 작은 블록도 최소 3개 이상의 QA를 생성해 의미적 밀도를 확보합니다.
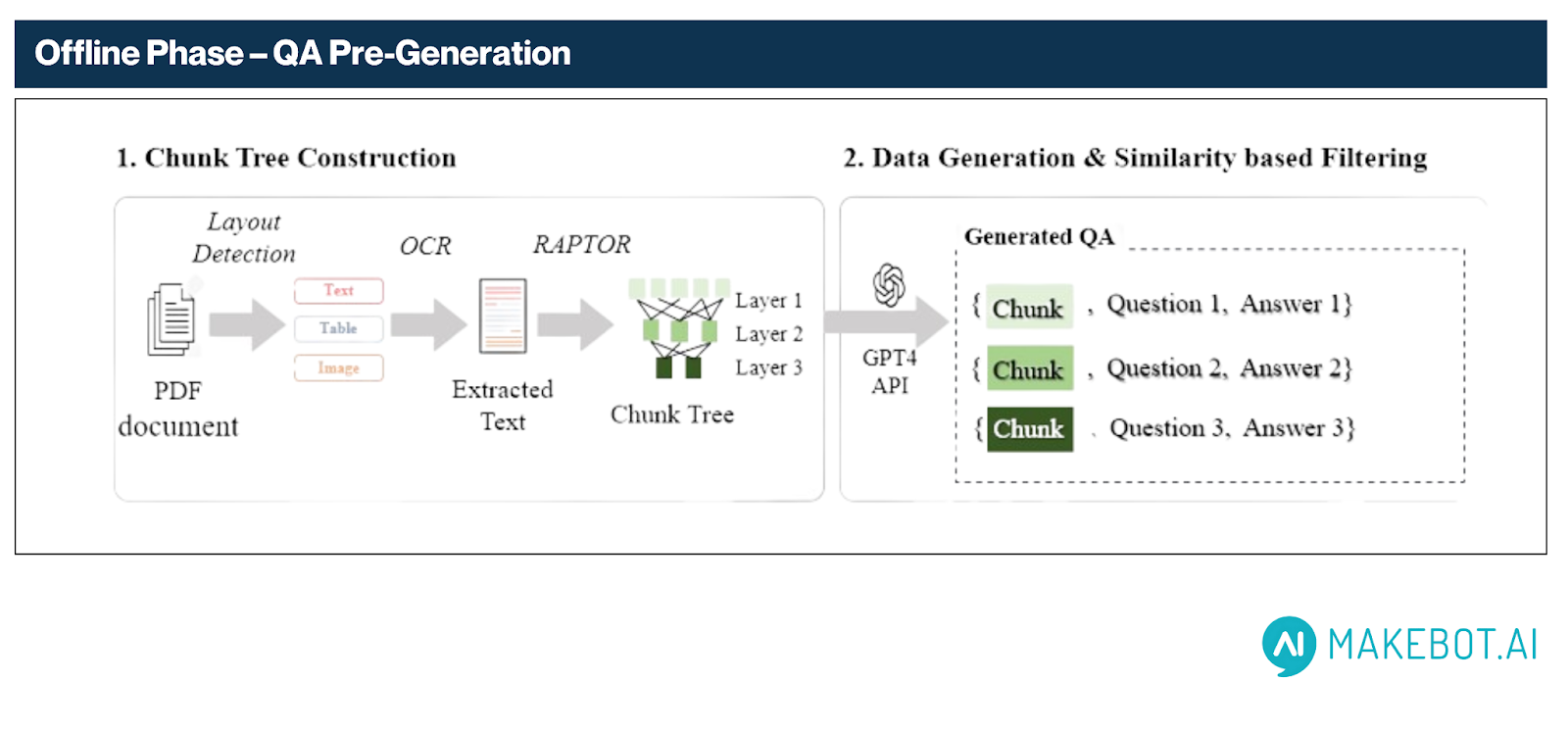
1.1. Chunk Tree Construction
- 레이아웃 인식 파싱 (Layout-Aware Parsing)
MinerU를 활용해 스캔된 PDF 내 텍스트 블록, 표, 그림 등 레이아웃 요소를 감지합니다. 시각적 요소(예: 표, 차트 등)는 GPT-4o를 활용해 자연어로 설명을 생성함으로써 이후 질의응답 정확도를 크게 향상시킵니다.
- OCR 추출 (OCR Extraction)
PaddleOCR을 통해 다단 컬럼, 내장 폰트, 스캔 품질이 낮은 문서에서도 텍스트를 정확히 추출합니다.
- RAPTOR 기반 계층적 청킹 (Hierarchical Chunking via RAPTOR)
RAPTOR 프레임워크에서 착안한 방식으로, 문서를 의미 단위 트리 구조로 정리합니다:
- 상위 노드: 전체 주제 흐름과 요약 정보 포함
- 하위 노드: 단락 수준의 세부 정보 유지
1.2. Data Generation
- 적응형 키워드 추출 (Adaptive Keyword Extraction)
GPT-4o-mini를 이용해 각 청크에서 의미 있는 키워드를 추출합니다. 상위 노드는 의미 밀도가 높기 때문에 더 많은 키워드를 배정하고, 하위 노드는 타겟 중심의 소수 키워드를 활용합니다.
- Chain-of-Thought QA 생성
각 키워드마다 GPT-4o-mini가 Chain-of-Thought 방식으로 QA 쌍을 생성합니다. 이를 통해 다음과 같은 이점을 확보합니다:
- 다양한 콘텐츠 범위 커버
- 문맥에 기반한 독립적인 질문
- 콘텐츠 중요도에 따라 QA 생성 수 자동 조절
2. 온라인 단계 – 질의 매칭 및 응답 생성
QA 베이스가 구축되면, 시스템은 실시간 서비스 모드로 전환되어 사용자 질의에 빠르게 대응합니다.
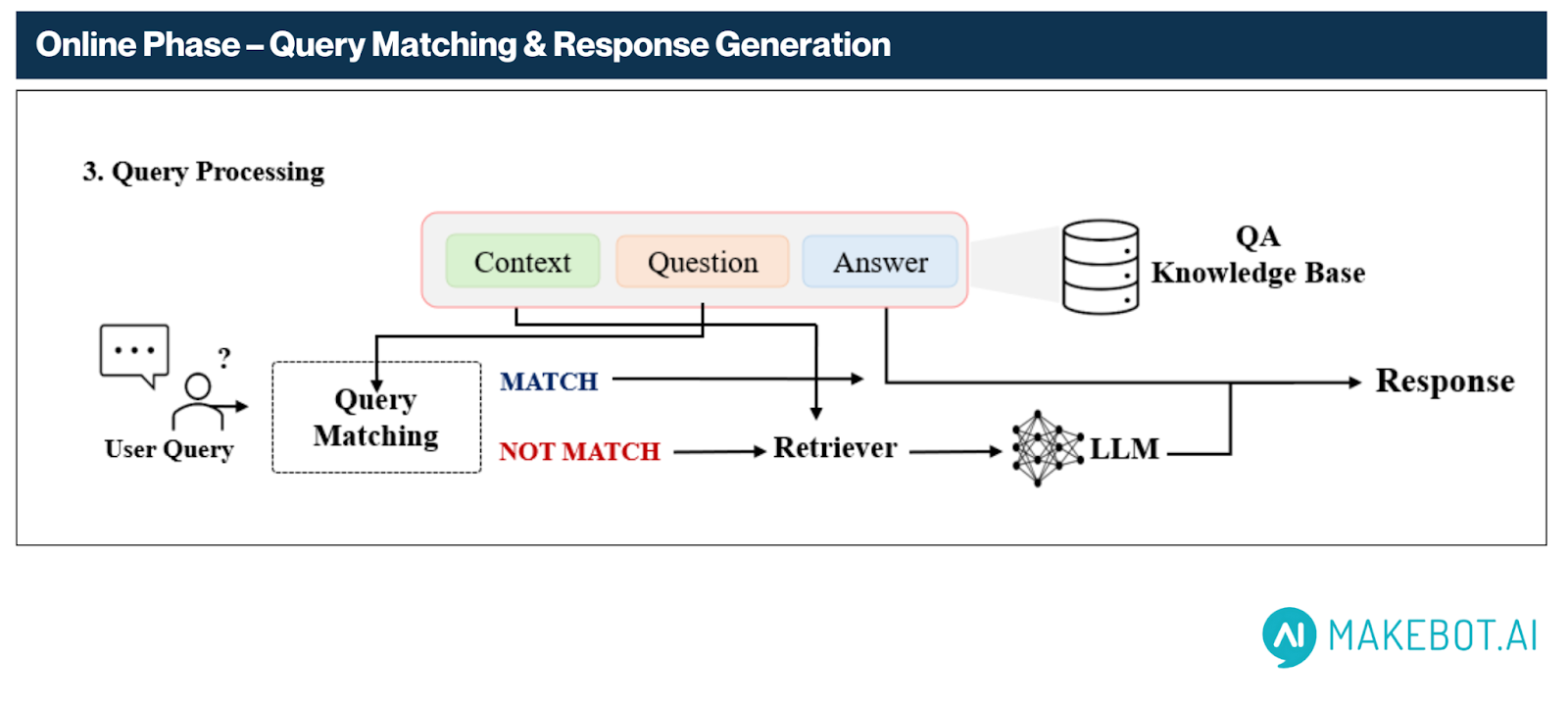
2.1. 의미 임베딩 기반 질의 매칭
- 사용자의 질문은 BGE-M3를 통해 임베딩되고, QA 지식 베이스의 사전 생성 질문들과 의미 유사도를 계산합니다.
- 유사도가 기준점(예: 0.9)을 초과하는 경우, 해당 QA의 정답을 즉시 반환합니다.
2.2. Fallback 메커니즘 – 검색 + 생성 조합
강한 매칭이 없을 경우, 시스템은 다음과 같이 동작합니다:
- 가장 유사한 상위 3개의 QA 쌍을 검색하고, 해당 문서 청크를 수집
- 이 청크들과 관련된 질문들을 함께 LLM에 전달하여 실시간 응답 생성
- 실험 결과, 질문을 함께 입력하는 방식이 성능 향상에 유의미하게 기여하는 것으로 확인되었습니다
3. 최종 응답 출력
최종적으로, 시스템은 두 가지 경로 중 하나로 응답을 반환합니다:
- 직접 매칭 경로: QA 지식 베이스에서 일치 응답을 직접 반환하며, LLM 호출이 필요 없습니다
- 생성 경로 (Fallback Generation): 고신뢰 매칭이 없을 경우, 관련 문맥을 기반으로 LLM을 통해 응답을 생성합니다
최적화와 트레이드오프: 속도, 비용, 품질의 균형 잡기
HybridRAG은 시스템 성능을 비용 효율성, 지연 시간, 응답 품질이라는 세 가지 핵심 요소에서 동시에 최적화하도록 설계되었습니다. 오프라인 QA 생성과 유연한 의미 유사도 기준(semantic threshold)을 결합함으로써, 실시간 LLM 호출에 대한 의존도를 줄이면서 더 복잡한 문서 유형에서 높은 응답 품질을 유지할 수 있습니다.
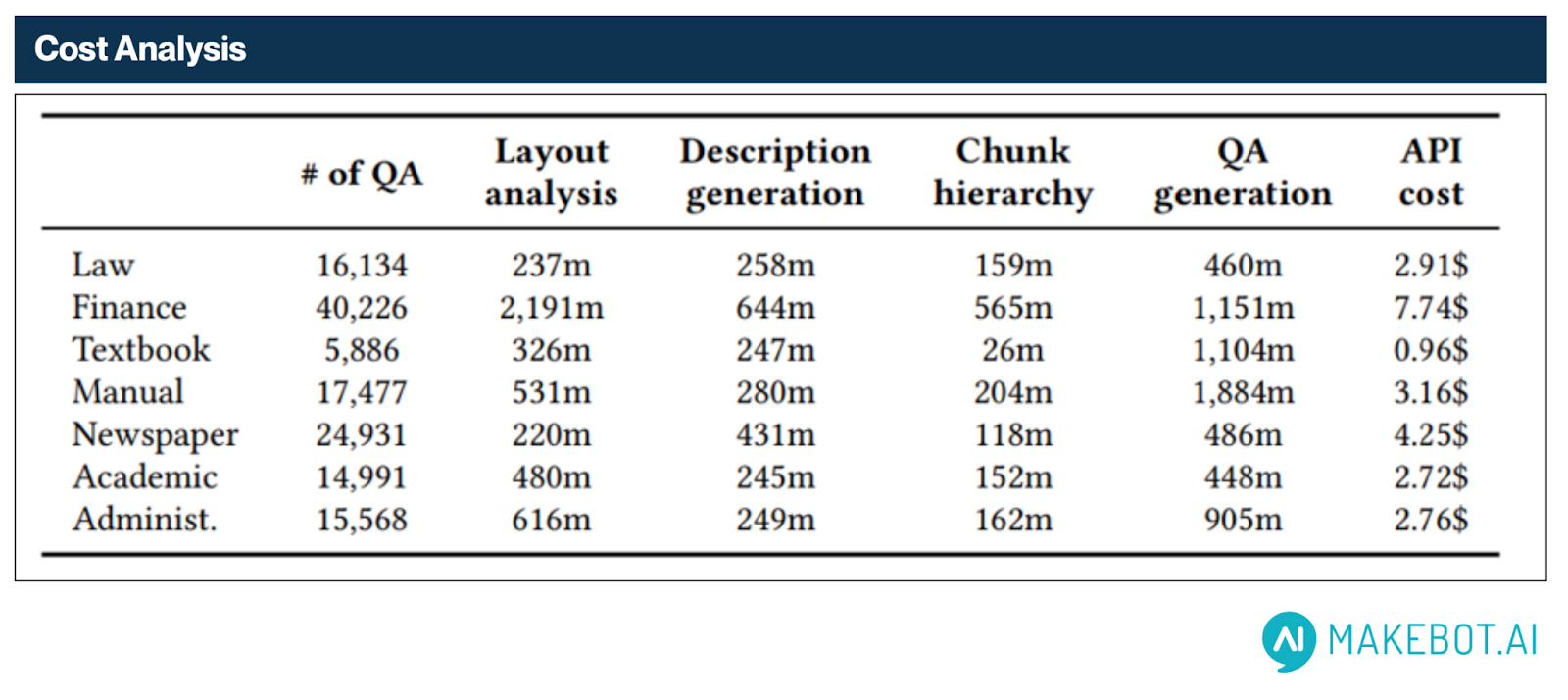
대규모 환경에서도 경제적인 비용 구조
HybridRAG은 LLM 연산의 대부분을 오프라인 단계로 이전시킴으로써 운영 비용을 획기적으로 절감합니다. 실시간 모델 호출 없이, 사전에 7개 도메인에 걸친 다양한 문서에서 130,000개 이상의 QA 쌍을 생성했습니다.
- 총 생성 비용: $24.50
- QA 한 쌍당 평균 비용: 약 0.018~0.019¢
도메인별 예시:
- Finance: 40,226개 QA 쌍 – $7.74
- Law: 16,134개 QA 쌍 – $2.91
- Academic: 14,991개 QA 쌍 – $2.72
이처럼 낮은 비용 구조 덕분에 HybridRAG은 높은 처리량이 요구되는 환경에서도 기존 LLM 기반 시스템보다 훨씬 경제적으로 운영될 수 있습니다.
Threshold 조정: 정확도 vs 커버리지
HybridRAG은 의미 유사도 임계값(semantic similarity threshold)을 기준으로 사전 QA 응답 반환 여부를 결정합니다. 다양한 임계값 분석 결과, 다음과 같은 특성이 확인되었습니다:
- Threshold 0.9:
- 약 13%의 질의만 QA 매치로 응답
- LLM 호출 비율 높아짐 → 품질 향상, 지연 시간 증가
- Threshold 0.7:
- 80% 이상의 질의를 사전 QA로 즉시 응답
- 응답 속도는 빨라지지만, 정답률은 다소 낮아질 수 있음
운영 팁:
- 정밀성, 컴플라이언스가 중요한 분야 (예: 금융, 법률): 높은 임계값(0.9) 권장
- 응답 속도, 커버리지가 중요한 고객 응대 서비스: 낮은 임계값(0.7) 적합
- 도메인 또는 질의 유형에 따른 동적 threshold 설정을 통해 최대 효용 달성 가능
HybridRAG의 실제 성능
OHRBench 벤치마크를 사용해 HybridRAG의 성능을 검증했습니다. 이 벤치마크는 7개 도메인의 실세계 PDF 1,261개와 검증된 QA 8,498쌍으로 구성되어 있으며, 전체 후보 15,317개 중 정확도와 RAG 적합성 기준으로 엄선되었습니다.
비교 대상
- Standard RAG: 사전 QA 없음, 단순 OCR 기반 청킹
- Simplified HybridRAG: 사전 QA 생성은 있으나 레이아웃 분석 및 계층 청킹 없음
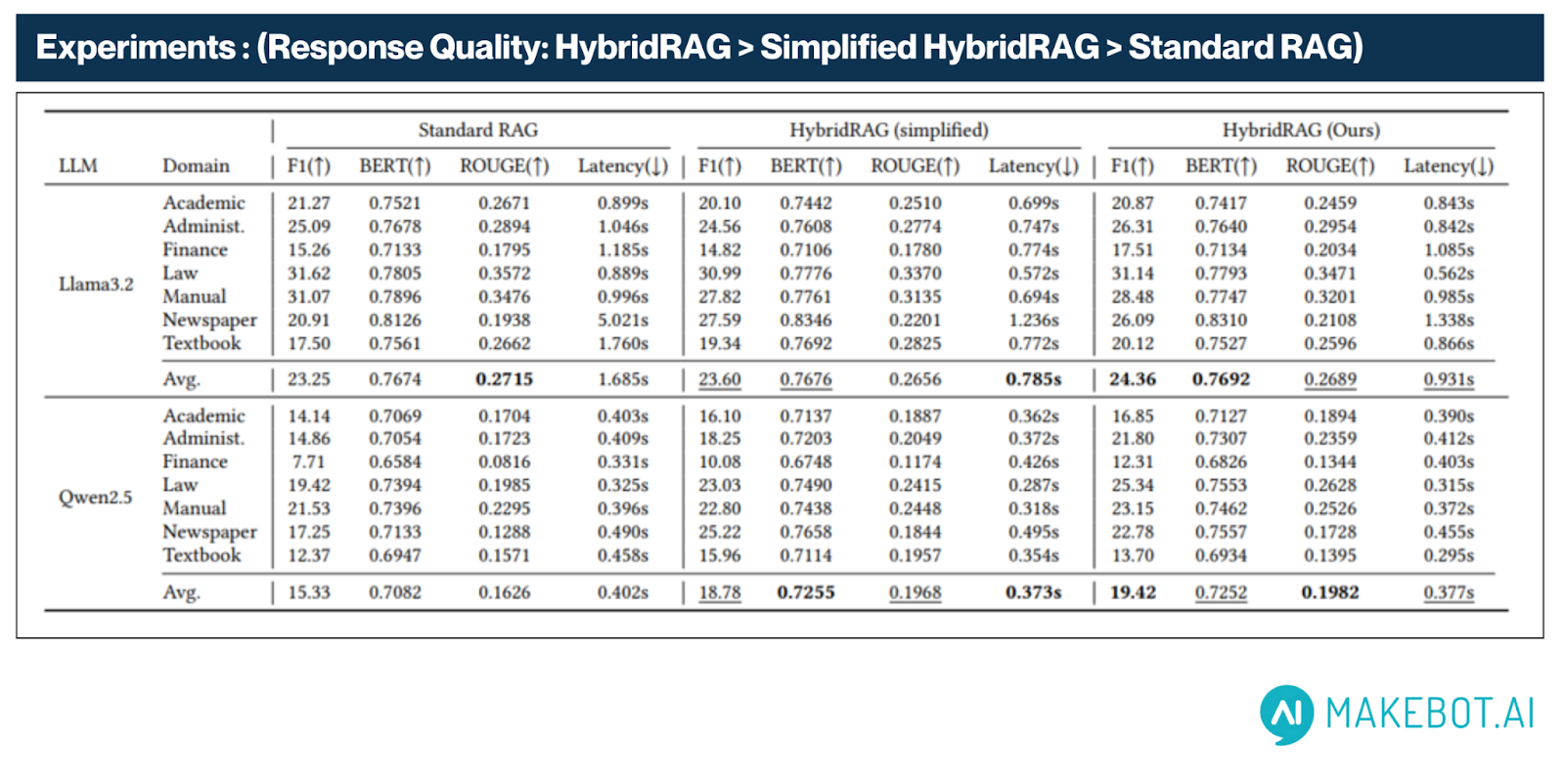
정량적 성능 지표
LLaMA3 및 Qwen2.5와 같은 다양한 LLM 백본에서 HybridRAG은 Standard RAG 및 Simplified RAG 대비 일관되게 우수한 성능을 보여주었습니다. 정확도(F1 Score), 의미적 품질, 지연 시간(latency) 전반에서 개선 효과가 확인되었습니다.
- F1 Score는 Standard RAG의 15.33에서 HybridRAG의 19.42로 상승하여, 26.6%의 상대적 향상을 기록했습니다. 이는 다양한 문서 유형에서 응답의 정확성과 문맥 정합성이 향상되었음을 나타냅니다.
- LLaMA3.2 환경에서는 HybridRAG이 평균 F1 Score 24.36을 기록해, Standard RAG의 23.25보다 우수한 결과를 보였습니다. 이는 강력한 LLM에서도 HybridRAG의 구조적 이점이 여전히 유효함을 보여줍니다.
- LLaMA3.2 환경에서는 HybridRAG이 평균 F1 Score 24.36을 기록해, Standard RAG의 23.25보다 우수한 결과를 보였습니다. 이는 강력한 LLM에서도 HybridRAG의 구조적 이점이 여전히 유효함을 보여줍니다.
- ROUGE Score는 0.1626에서 0.1982로 상승하여, 참조 답변과의 n-그램 및 어휘 일치율이 개선되었습니다. 이는 기술 문서나 구조적 문서 응답에서 특히 중요한 요소입니다.
- BERT Score는 0.7082에서 0.7252로 증가해, 시스템이 생성한 응답과 실제 정답 간의 의미적 일치도가 개선되었음을 보여줍니다. 특히 LLaMA3.2 환경에서는 HybridRAG이 0.7692, Standard RAG이 0.7674를 기록해, 모델에 관계없이 의미 정합성 유지에 탁월한 성능을 입증했습니다.
- 지연 시간(Latency)은 평균 0.402초(Standard RAG)에서 0.377초(HybridRAG)로 줄어들어, 6.2% 응답 시간 단축이 이루어졌습니다. 의미 기반 매칭과 Fallback 메커니즘이 추가되었음에도 불구하고, 성능은 오히려 향상되었습니다. LLaMA3.2 기반에서도 HybridRAG은 평균 0.931초로, 1.685초였던 기존보다 현저히 빠른 응답 속도를 보여주었습니다.
- NVIDIA RTX 3090 환경에서 진행된 지연 시간 테스트에서도, LLaMA3.2와 같은 고성능 LLM을 사용했을 때에도 HybridRAG의 우수한 처리 속도가 확인되었습니다.
이러한 성능 향상은 LLaMA3.2와 Qwen2.5 등 서로 다른 LLM에서 모두 일관되게 관측되었으며, HybridRAG이 모델에 구애받지 않고 성능을 끌어올릴 수 있는 모델-아그노스틱(model-agnostic) 프레임워크임을 의미합니다. 대규모 모델이든, 경량화된 모델이든 관계없이 HybridRAG은 더 빠르고 정확하며 문맥을 고려한 응답을 제공하여, 엔터프라이즈 환경에 적합한 문서 QA 시스템으로 기능할 수 있습니다.
정성적 QA 평가 (G-Eval 기반)
LLM 기반 자동 평가 도구(G-Eval)를 통해 HybridRAG의 사전 생성 QA 응답을 OHRBench의 인간 평가 기준과 비교했습니다.
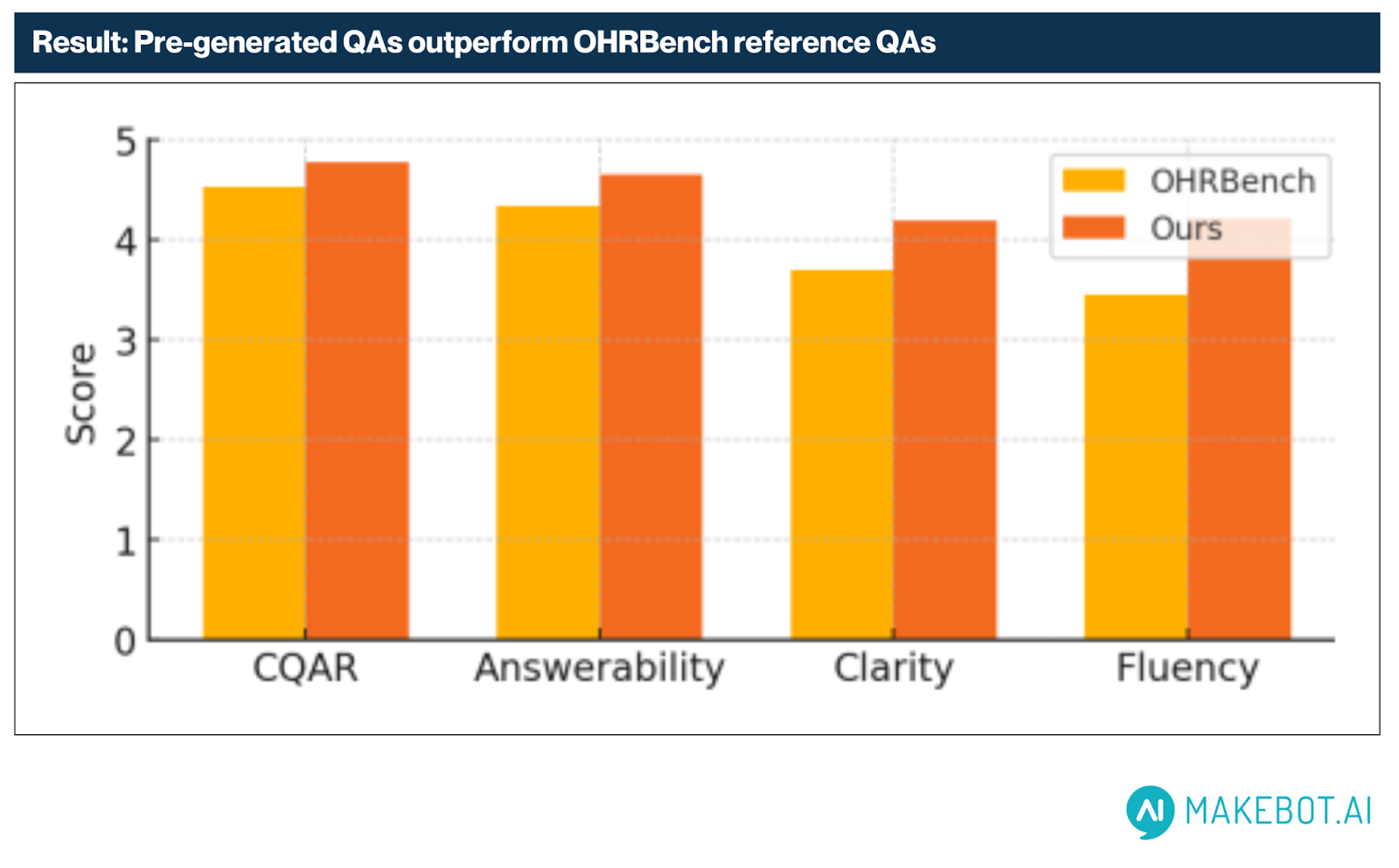
평가 결과, 모든 항목에서 지속적인 우위를 나타냈습니다:
- 유창성 (Fluency): +0.76 (가장 큰 향상폭)
- 명확성 (Clarity): +0.50
- 답변 가능성 (Answerability): +0.31
- 문맥 기반 관련성 (CQAR): +0.24
이러한 결과는 Chain-of-Thought 방식과 키워드 기반 QA 생성 전략이 인간 수준에 가까운 고품질 응답을 만들어냄을 잘 보여줍니다.
전략적 프레임과 리더십, 브랜드 비전
메이크봇 김지웅 대표가 이끄는 인공지능 비전
HybridRAG: A Practical LLM-based ChatBot Framework』라는 혁신적인 연구는 메이크봇의 CEO 김지웅 의해 기획되고, 주도적으로 개발되었으며, 특허까지 등록된 프로젝트입니다. 그는 전략적 리더십과 기술적 아키텍처 설계를 모두 아우르는 인물로, LLM(대규모 언어 모델) 과 RAG(검색 기반 생성 기술) 분야에서 메이크봇의 혁신을 이끌어온 주역입니다.
김지웅 비전을 말하는 리더이자, 직접 행동하는 기술인입니다. 그의 리더십 아래 메이크봇의 기술은 한국의 실제 비즈니스 현장에 적용되어 실질적인 솔루션으로 구현되었고, 이 성과는 메이크봇이 국내 LLM·RAG 분야를 선도하는 기업으로 자리 잡는 데 결정적 역할을 했습니다. 특히 정보 검색 분야에서 세계 최고 권위를 자랑하는 SIGIR 2025에서 HybridRAG을 발표하며, 이 성과는 글로벌 무대에서도 인정받았습니다.
🇰🇷 한국의 기술을 세계 AI 지도 위에 올리다
하지만 김지웅 목표는 단순한 기술 개발에 그치지 않습니다. 그는 기술의 실제 효용, 즉 "사람을 위한 AI"에 더 큰 열정을 가지고 있습니다. 그의 포커스는 분명합니다—사람과 조직이 더 똑똑하고 자연스럽게 연결되도록 돕는 도구를 만드는 것입니다.

김지웅 대표의 메세지
“우리는 이론적인 성과를 위해 일하는 것이 아닙니다. 우리의 목표는 현실의 문제를 해결하고, AI가 일상 속에서 실제 가치를 제공할 수 있도록 하는 것입니다.”.이처럼 해결 중심적이고 실용적인 마인드셋은 메이크봇이 AI 분야의 선두에 설 수 있는 핵심 원동력이 되어 왔습니다.
한국과 글로벌 AI 생태계에 주는 의미
ACM SIGIR은 정보 검색 분야에서 세계적으로 가장 권위 있는 학술 대회입니다. 이 무대에서 HybridRAG이 발표되었다는 사실은, 한국이 더 이상 단순한 참여자가 아닌, AI 혁신의 흐름을 만들어가는 주체로서 자리매김하고 있다는 강력한 신호입니다.
메이크봇의 LLM 및 RAG 연구는 단순한 기술 개발을 넘어선 국가적인 성공 사례입니다. 깊이 있는 연구, 똑똑한 문제 해결, 실제 기술 구현이 조화를 이루며, HybridRAG은 비정형 데이터를 더 빠르고 정교하게 처리하는 혁신적 솔루션으로 실질적인 비즈니스 가치를 제공하도록 설계되었습니다.
LLM과 RAG 기술을 한 단계 더 끌어올리기 위한 메이크봇의 여정은 지금도 전속력으로 진행 중이며, 그 속도는 전혀 느려지지 않고 있습니다.
더 많은 연구 성과와 확장, AI 분야의 중요한 순간들을 위해 Makebot.ai를 팔로우하세요. 지능형 정보 검색이 향할 다음 방향을 지켜봐 주시기 바랍니다. 이 이야기는 지금도 계속 쓰여지고 있습니다
About This Article
본 아티클은 메이크봇의 글로벌 리서치 조직이 영어로 초안을 작성한 후, 국내 엔터프라이즈 환경과 시장 맥락에 맞춰 한국어로 재구성·편집되었습니다. 메이크봇은 단순한 번역이나 요약이 아닌, 글로벌 AI 시장에서 논의되는 구조적 변화와 기술 흐름을 한국 기업이 실제로 적용 가능한 전략 언어로 전환하는 것을 콘텐츠의 핵심 원칙으로 삼고 있습니다. 본 아티클에 담긴 관점과 해석은 메이크봇이 수행해 온 다수의 엔터프라이즈 AI 프로젝트에서 축적된 실무 경험, 글로벌 리서치 조직의 지속적인 시장·기술 분석, 그리고 메이크봇 CEO의 기술적·전략적 검토를 거쳐 완성되었습니다.
This article is also available in English.