

최근 의료기관의 AI 도입은 실험적 파일럿 단계를 넘어 실제 운영 환경으로 확장되고 있습니다. 진료 안내 자동화, 임상 문서 작성 지원, 영상 판독 보조 등 다양한 영역에서 대규모 언어 모델(LLM)의 활용이 가속화되고 있습니다.
그러나 AI가 임상 의사결정과 직접 연결되는 순간, 가장 중요한 질문은 모델의 성능이 아니라 신뢰성입니다. 작은 부정확성 하나가 진단 방향을 바꾸고, 환자 안전 리스크로 이어질 수 있기 때문입니다.
이러한 맥락에서 최근 의료 AI 분야의 핵심 화두는 단순한 모델 고도화가 아니라, 근거 기반 설계(Grounded Architecture) 입니다. 모델이 무엇을 생성할 수 있는가보다, 무엇에 근거해 생성하는가가 더 중요해지고 있습니다.
이 글에서는 임상 AI에서 근거 중심 LLM 아키텍처가 왜 필수적인지, 그리고 RAG 기반 시스템 설계가 어떻게 환각을 구조적으로 통제할 수 있는지를 살펴봅니다.
이 글에서는 다음을 중심으로 살펴봅니다.
- RAG(검색 증강 생성)이 임상 LLM(대규모 언어 모델)의 환각을 어떻게 줄이는지
- 단순한 구현 방식이 왜 여전히 실패하는지
- 실제 의료 환경에서 신뢰 가능한 수준으로 운영하기 위해 어떤 시스템 설계가 필요한지
엔터프라이즈 LLM 구축의 함정: 겉으로 보이지 않는 비용들. 여기서 더 읽어보세요!
핵심 기술 용어 정리
Entity Probing. 임상 LLM이 특정 질환이나 소견을 정확히 식별하는지 평가하기 위해, 참조 보고서를 기반으로 구조화된 Yes/No 질문을 수행하는 검증 방식입니다.
Multimodal Retrieval. RAG 구조 내에서 텍스트뿐 아니라 의료 영상 등 여러 데이터 모달리티를 함께 검색하여 근거 기반 생성을 강화하는 전략입니다.
Context Noise. 검색 증강 생성 과정에서 불필요하거나 중복되거나 오해를 유발하는 정보가 컨텍스트에 포함되어 생성 품질을 저하시킬 때 발생하는 노이즈를 의미합니다.
Knowledge Boundary. 대규모 언어 모델은 학습 데이터에서 습득한 패턴 범위 내에서만 출력을 생성할 수 있다는 근본적인 한계를 가집니다. 이 지식 경계를 벗어날 때 환각이 발생할 가능성이 높아집니다.
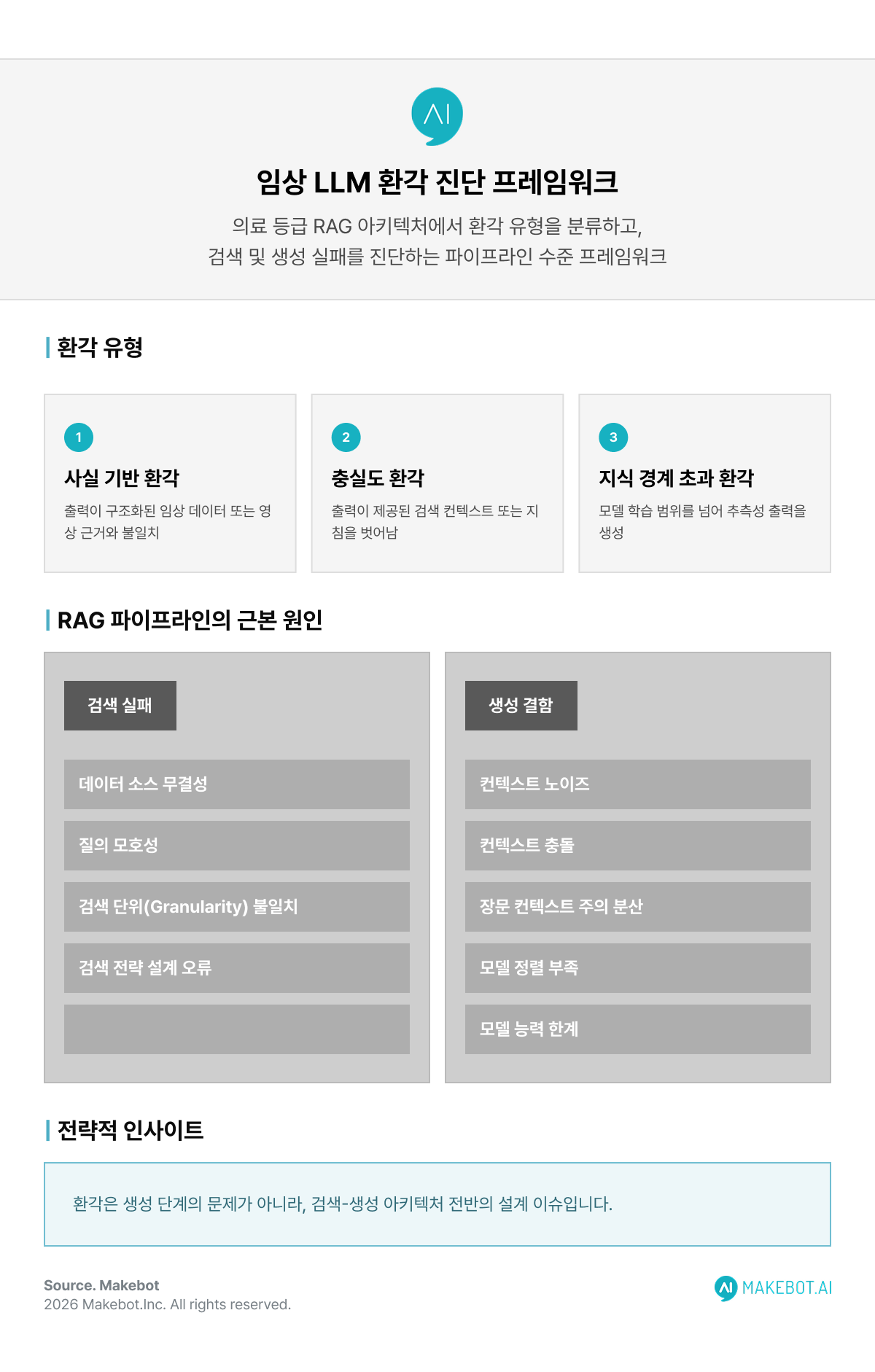
임상 AI 개발에서 환각이 구조적으로 어려운 이유
현대 LLM(대규모 언어 모델)은 확률 기반 시퀀스 모델입니다. 이 모델은 “그럴듯한 다음 문장”을 예측하도록 설계되었으며, 사실의 정확성을 보장하도록 설계된 것은 아닙니다.
임상 환경에서 환각은 다음과 같은 형태로 나타납니다.
- 사실 기반 환각(Factual Hallucination): 영상 또는 구조화 데이터와 일치하지 않는 소견을 생성하는 현상입니다.
- 충실도 환각(Faithfulness Hallucination): 제공된 컨텍스트나 지침을 벗어난 응답을 생성하는 현상입니다.
- 지식 경계 초과 환각 (Knowledge-Boundary Hallucination): 모델의 지식 범위를 넘어선 질문에 대해 추측성 답변을 생성하는 현상입니다.
검색 증강 생성 시스템 관련 연구는 환각의 원인을 크게 두 가지 범주로 구분합니다.
1. 검색 단계 실패 (Retrieval Failure)
- 데이터 소스 품질 문제입니다.
- 모호하거나 복잡한 질의입니다.
- 부적절한 검색 단위 설정입니다.
- 비효율적인 검색 전략입니다.
2. 생성 단계 결함 (Generation Deficiency)
- 컨텍스트 노이즈입니다.
- 상충되는 정보입니다.
- 긴 컨텍스트 내 정보 왜곡입니다.
- 정렬(Alignment) 부족입니다.
- 모델 역량의 구조적 한계입니다.
중요한 점은, 환각이 단순히 생성 모델만의 문제가 아니라는 사실입니다. 이는 검색-생성 파이프라인 전체의 시스템 설계 문제입니다.
이러한 구조적 문제는 영상 판독뿐 아니라 의료 상담 및 환자 문의 자동화 영역에서도 동일하게 발생합니다. 특히 진료 안내, 보험 적용 범위 설명, 시술 전후 상담과 같은 대화형 응답에서는 작은 부정확성도 신뢰 리스크로 확장될 수 있습니다.

RAG(검색 증강 생성)이 지식 경계를 확장하는 방식
파라미터 기반 LLM의 가장 큰 한계는 고정된 지식 경계(Knowledge Boundary)입니다. 의료 가이드라인은 지속적으로 업데이트되며, 병원별 프로토콜도 서로 다릅니다. 검색 증강 생성은 이를 다음과 같은 방식으로 보완합니다.
- 외부 도메인 지식(문서, 보고서, 의료 영상)을 검색합니다.
- 검색된 근거를 프롬프트 컨텍스트에 주입합니다.
- 해당 근거에 기반하여 응답을 생성합니다.
이론적으로 이는 모델이 학습된 파라미터에만 의존하지 않도록 하여 환각 가능성을 낮추는 구조입니다.
그러나 실제 의료 환경, 특히 멀티모달 환경에서는 텍스트 기반 RAG만으로는 충분하지 않다는 점이 확인되고 있습니다.
임상 영상에서의 Visual RAG(검색 증강 생성)의 진화
임상 영상 분야에서 주목할 만한 진전은 Visual Retrieval-Augmented Generation(V-RAG) 의 등장입니다. 이 접근은 검색된 텍스트뿐 아니라 검색된 의료 영상까지 추론 과정에 함께 통합한다는 점에서 기존 RAG(검색 증강 생성) 구조와 차별화됩니다.
흉부 X-ray 보고서 생성(MIMIC-CXR)과 의료 캡셔닝 데이터셋(MultiCaRe)을 활용한 실험에서, V-RAG는 다음과 같은 성과를 보였습니다.
- 엔티티 단위 근거 정확도(grounding accuracy) 향상
- 질환 탐지(entity probing) F1 점수 개선
- 생성된 보고서 내 환각 엔티티 감소
특히 성능 지표 측면에서 의미 있는 개선이 확인되었습니다.
- 기존 Med-MLLM F1 (MIMIC-CXR): 0.381
- 텍스트 기반 RAG(검색 증강 생성) (RAT/Img2Loc): 0.711
- V-RAG: 0.721
- 파인튜닝된 V-RAG: 0.751
이러한 향상은 단순 평균 성능 개선에 그치지 않았습니다. 데이터 희소성으로 인해 환각이 특히 빈번하게 발생하는 희귀 엔티티 영역에서도 성능 개선이 확장되었습니다.
이는 임상 AI 개발 관점에서 중요한 의미를 갖습니다. 희귀 질환이나 드문 영상 소견은 학습 데이터가 충분하지 않기 때문에 LLM(대규모 언어 모델)이 추측에 의존할 가능성이 높습니다. Visual RAG(검색 증강 생성)는 이러한 구조적 한계를 완화하며, 보다 근거 중심의 추론을 가능하게 합니다.
결과적으로, 멀티모달 기반 검색 증강 생성은 임상 영상 해석에서 환각을 줄이고 보고서 신뢰도를 높이는 실질적 대안으로 자리 잡고 있습니다.
왜 중요한가
텍스트 기반 검색은 “유사한 보고서”가 동일한 임상 상황을 반영한다고 가정합니다. 그러나 실제로는 유사한 표현을 사용하더라도 영상 패턴은 미묘하게 다를 수 있습니다.
Visual RAG는 다음 요소를 동시에 비교합니다.
- 질의 영상
- 유사 영상
- 해당 영상의 보고서
이러한 멀티모달 기반 삼각 검정 구조는 근거 기반 추론의 정밀도를 높이고, LLM의 환각 가능성을 줄이는 데 기여합니다.

검색 증강 생성 기반 임상 AI 개발 아키텍처
신뢰 가능한 수준의 AI 개발을 위해서는 검색 증강 생성 파이프라인을 체계적으로 설계해야 합니다.
임베딩 및 검색 레이어
- 바이오메디컬 인코더입니다.
- 벡터 저장소입니다.
- 근사 최근접 탐색(ANN)입니다.
설계 시 고려 요소는 다음과 같습니다.
- 검색 단위 설정(영상이 단위 vs 보고서 섹션 단위)입니다.
- Top-k 최적화입니다.
- 도메인 의미론과 임베딩 정렬입니다.
멀티모달 컨텍스트 구성
- 검색된 영상(I₁…Iₖ)입니다.
- 검색된 보고서(R₁…Rₖ)입니다.
- 질의 영상입니다.
- 구조화된 프롬프트 가이드입니다.
이 단계에서 조립이 잘못되면 컨텍스트 노이즈가 증가하거나 주의(attention)가 분산되어 성능이 저하됩니다.
생성 및 검증 단계
- 임상 특화 LLM입니다.
- 구조화 프롬프팅(Entity Probing, Yes/No 제약 등)입니다.
- 필요 시 상위 텍스트 모델을 통한 재작성 레이어입니다.
실제 운영 환경에서는 다음과 같은 다단계 전략이 활용됩니다.
- 초기 보고서를 생성합니다.
- NER 기반으로 엔티티를 추출합니다.
- RAG 기반으로 엔티티를 검증합니다.
- 시니어 리뷰 스타일 프롬프트를 적용하여 재작성합니다.
이 접근은 RadGraph-F1 기준 약 19%의 상대적 성능 개선을 보였습니다.
Entity Probing: 환각 진단 도구로서의 활용
ROUGE와 같은 전통적인 자동 평가 지표는 임상적 부정확성을 충분히 포착하지 못하는 경우가 많습니다. 특히 의료 보고서에서는 표현 유사도가 아니라 사실 정확성이 핵심이기 때문입니다.
이때 Entity Probing은 보다 임상 친화적인 평가 방식을 제공합니다.
평가 절차는 다음과 같습니다.
- 보고서에서 질환 엔티티를 추출합니다.
- “환자에게 기흉이 있습니까?”와 같은 폐쇄형 질문을 생성합니다.
- 모델의 응답을 실제 정답(Ground Truth)과 비교합니다.
MIMIC-CXR의 9,411개 VQA 쌍과 MultiCaRe의 21,653개 쌍을 대상으로 한 실험에서, 엔티티 단위 F1 점수는 환각을 측정하는 신뢰 가능한 지표로 확인되었습니다.
이 접근 방식은 단어 수준 유사도에 의존하는 어휘 편향(lexical bias) 을 피하고, 모델이 실제로 사실을 정확히 이해하고 있는지를 직접적으로 평가합니다.
임상 RAG(검색 증강 생성) 구현의 트레이드오프
RAG(검색 증강 생성)은 강력한 접근 방식이지만, 새로운 실패 모드 역시 함께 가져옵니다.
검색 단계 실패 (Retrieval Failure)
- 최신 가이드라인이 반영되지 않은 데이터
- 특정 기관에 편향된 데이터셋
- 부정확한 질의 구성
- 의미 유사도에 대한 과도한 의존
검색 품질이 낮으면, 환각을 줄이기는커녕 오히려 증폭시킬 수 있습니다.
즉, 잘못된 근거는 잘못된 생성으로 이어집니다.
컨텍스트 노이즈 (Context Noise)
너무 많은 문서를 검색할 경우:
- 정보 엔트로피 증가
- 주의(attention) 분산
- 사실 정확도 저하
반대로 너무 적게 검색하면:
- 정보 범위 제한
- 파라미터 기반 사전 지식에 대한 의존 증가
적절한 균형이 핵심입니다.
컨텍스트 충돌 (Context Conflict)
검색된 근거가 모델 내부 지식과 충돌할 경우, 생성 과정에서 다음과 같은 문제가 발생할 수 있습니다.
- 내부 지식을 우선시
- 상충 정보를 혼합
- ‘하이브리드 환각’ 생성
이는 검색 증강 생성이 단순히 근거를 추가한다고 해서 자동으로 안전해지지 않음을 보여줍니다.
지연 시간과 비용 (Latency & Cost)
임상 환경에서의 LLM(대규모 언어 모델) 배포는 다음 요소를 동시에 고려해야 합니다.
- 검색 빈도
- 멀티 홉(Multi-hop) 검색 여부
- 컨텍스트 윈도우 제한
- GPU 메모리 제약
특히 실제 AI 개발 환경에서는 정확도뿐 아니라 비용 효율성과 응답 지연 관리 역시 중요한 운영 지표입니다.
AI 파일럿은 성공하지만 전사 확장은 실패하는 이유. 더 보기!
멀티 이미지 추론을 위한 파인튜닝 전략
주요 대규모 언어 모델의 한계 중 하나는 멀티 이미지 추론 능력의 부족입니다.
다음 세 가지 파인튜닝 과제가 V-RAG(검색 증강 생성)의 성능 개선에 효과적인 것으로 나타났습니다.
- 이미지-텍스트 연관 학습
- 이미지 초점 모호성 해소
- 유사 정보 추출 기반 학습
파인튜닝된 모델은 다양한 설정에서 F1 점수 향상을 보였으며, 단일 이미지 기반으로 학습된 모델조차 V-RAG(검색 증강 생성) 환경에서 활용 가능해졌습니다.
이는 실질적인 AI 개발 관점에서 중요한 의미를 가집니다. 전문적인 멀티 이미지 사전 학습에 대한 의존도를 낮추어, 검색 증강 생성 구조를 보다 널리 적용할 수 있게 만들기 때문입니다.
임상 LLM(대규모 언어 모델) 환각 감소를 위한 시스템 전략
V-RAG(검색 증강 생성)만으로는 충분하지 않습니다. 보다 포괄적인 완화 전략이 필요합니다.
검색 최적화
- 도메인 특화 임베딩 모델
- 적응형 Top-k 전략
- Dense + Sparse 하이브리드 검색
- 구조화된 지식 그래프 통합
프롬프트 엔지니어링
명확한 지시문, 역할 기반 프레이밍(Role-based framing), 단계적 추론(Chain-of-Thought) 기법 등은 환각 감소에 실질적인 영향을 미칩니다.
프롬프트 설계는 단순 표현 개선이 아니라, 생성 경로를 통제하는 설계 전략입니다.
생성 후 탐지 및 보정
환각을 완전히 제거하는 것은 현실적으로 어렵습니다. 따라서 탐지 및 수정 레이어가 필수적입니다.
- 엔티티 일관성 검증
- 교차 모델 검증
- 신뢰도 기반 임계값 설정
- 상위 성능 모델을 활용한 재작성 루프
이러한 후처리 전략은 의료 환경에서의 안전성을 한 단계 끌어올립니다.
임상적 함의
파라미터 기반 LLM(대규모 언어 모델)에서 검색 기반 구조로의 전환은 임상 AI 시스템의 근본적 변화를 의미합니다.
RAG(검색 증강 생성)는 다음을 가능하게 합니다.
- 지식 경계의 동적 확장
- 희귀 엔티티 환각 감소
- 구조화된 보고서 정확도 향상
- 생성 이후 임상 보정 워크플로우 구현
그러나 이는 만능 해결책이 아닙니다.
검색 증강 생성은 아키텍처 복잡성을 증가시키며, 새로운 실패 모드를 동반합니다.
임상 안전성을 확보하기 위해서는 다음이 필수적입니다.
- 정제된 검색 코퍼스
- 검색 성능에 대한 체계적 평가
- 멀티모달 기반 근거 고정(Grounding)
- 지속적 모니터링 체계
결론 : 근거 중심 LLM이 임상 AI의 표준이 됩니다
임상 대규모 언어 모델에서의 환각은 단순한 학습 오류가 아닙니다. 이는 확률적 생성 모델이 갖는 구조적 특성입니다. 따라서 문제의 본질은 모델의 크기가 아니라, 검색·생성·검증을 포함한 시스템 설계에 있습니다.
이 원리는 임상 영상 보고서 생성뿐 아니라, 병원 AI 상담·환자 문의 자동화 영역에도 동일하게 적용됩니다. 진료 안내, 보험 문의, 질환 설명과 같은 대화형 응답에서 근거 고정이 부족할 경우, 작은 오류도 신뢰 리스크로 확장될 수 있습니다.
RAG 기반 아키텍처는 단순 기능이 아니라, 의료 AI의 안전성과 확장성을 동시에 확보하기 위한 운영 설계 전략입니다. 멀티모달 근거 통합, 엔티티 단위 검증, 검색 최적화, 후처리 보정 레이어는 고위험 영역뿐 아니라 의료 상담 자동화에서도 점점 필수 요소가 되고 있습니다.
앞으로 의료 AI의 경쟁력은 어떤 모델을 사용하는지가 아니라, 얼마나 근거 중심으로 설계되어 있는가에 의해 결정될 것입니다.
메이크봇은 임상 AI와 의료 상담 자동화 모두에서 근거 고정 아키텍처를 기반으로 한 운영형 RAG 설계를 지원합니다. 파일럿을 넘어 안정적 운영 단계로 확장하고자 한다면, 지금이 시스템 수준 재설계를 검토할 시점입니다.
의료 상담 자동화 시스템에서 잘못된 진료 안내나 보험 정보 제공은 단순 오류가 아니라 법적·평판 리스크로 확장될 수 있습니다. 근거 기반 설계는 이러한 리스크를 구조적으로 낮추는 운영 전략입니다.
👉 AI 전환 시작하기: www.makebot.ai
📩 문의: b2b@makebot.ai
About This Article
본 아티클은 메이크봇의 글로벌 리서치 조직이 영어로 초안을 작성한 후, 국내 엔터프라이즈 환경과 시장 맥락에 맞춰 한국어로 재구성·편집되었습니다. 메이크봇은 단순한 번역이나 요약이 아닌, 글로벌 AI 시장에서 논의되는 구조적 변화와 기술 흐름을 한국 기업이 실제로 적용 가능한 전략 언어로 전환하는 것을 콘텐츠의 핵심 원칙으로 삼고 있습니다. 본 아티클에 담긴 관점과 해석은 메이크봇이 수행해 온 다수의 엔터프라이즈 AI 프로젝트에서 축적된 실무 경험, 글로벌 리서치 조직의 지속적인 시장·기술 분석, 그리고 메이크봇 CEO의 기술적·전략적 검토를 거쳐 완성되었습니다.
This article is also available in English.





