
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy
Discover how Korea’s Makebot is leading AI innovation with its HybridRAG chatbot framework.


Hyuna Jeon, undergraduate researcher from Hanyang University, presents Makebot’s HybridRAG framework at SIGIR 2025.
PADUA, ITALY — July 17, 2025
On July 17, we had the incredible opportunity to present Makebot’s latest research on AI-driven document retrieval at the world’s leading academic conference in information retrieval—SIGIR 2025. Hosted in the historic city of Padua, Italy, this event brought together global experts from academia and industry to explore breakthroughs in search, large language models (LLMs), recommender systems, and more.
Our paper, “HybridRAG: Aduring the Practical LLM-based Chatbot Framework based on Pre-Generated Q&A over Raw Unstructured Documents,” was presented by Hyuna Jeon, an undergraduate researcher at Hanyang University. The research was led and developed by Jiwoong Kim, CEO of Makebot, who also filed the related patent and designed the LLM and RAG engines powering the system.
🏛️ Welcome to Padua: A City of Knowledge

It’s hard to imagine a more fitting place for an academic conference than Padua. As one of Italy’s oldest university cities, the atmosphere here blends Renaissance charm with intellectual curiosity. Narrow streets, sun-soaked piazzas, and centuries-old buildings surrounded us as we prepared for our session.
🏢 The Venue: Centro Congressi – Fiera di Padova



SIGIR 2025 was held at the Centro Congressi in Fiera di Padova, a modern convention center with excellent facilities for researchers and industry professionals alike. Inside, the halls buzzed with energy as conversations unfolded in every corner—from deep algorithmic theory to real-world AI deployment challenges.
🧠 On Stage at Mantegna Hall 2


Our presentation took place in Mantegna Hall 2 on the third floor. The room quickly filled with curious attendees, ready to learn about HybridRAG—a practical framework that tackles the limitations of traditional Retrieval-Augmented Generation (RAG) systems.
We proposed a scalable, cost-efficient architecture that uses pre-generated Q&A pairs alongside LLMs to provide faster, more accurate answers over unstructured documents. This approach is already being tested in real-world applications across Korea.
🍝 Networking Over Lunch – The Italian Way

After our session, we joined fellow researchers for a relaxed lunch break. Over pasta and espresso, we exchanged ideas with peers from Europe, the U.S., and Asia—discussing everything from performance benchmarks to LLM deployment in multilingual settings.
📌 Poster Presentation: Up Close with HybridRAG
Later in the day, we participated in the poster presentation session, which gave us a chance to speak one-on-one with attendees. Many expressed interest in the practical nature of our approach, especially how we validated performance gains over standard RAG models.
We were proud to share how this research, initiated by our CEO Jiwoong Kim, reflects Makebot’s commitment to building deployable, scalable AI tools—not just theoretical models.
HybridRAG: Solving Real-World Document QA Challenges
Traditional RAG systems face a fundamental bottleneck when processing unstructured documents like PDFs containing complex layouts, tables, and mixed content types. While conventional approaches assume well-structured text sources and perform document retrieval followed by on-the-fly answer generation, this creates significant performance issues in enterprise environments.
The Core Problems HybridRAG Addresses
Slow and Inefficient at Runtime. Traditional RAG systems run a full retrieval and generation process for every query. This leads to high latency and computational load—especially problematic in high-traffic environments.
Struggles with Complex Documents. Standard RAG relies on paragraph-level chunking, which breaks down with messy or structured formats like PDFs. It often fails to handle financial tables, nested sections, and figures, resulting in poor coverage and fragmented context.
Loses Context Across Sections. Documents with interlinked parts—like legal references or technical manuals—require context to be preserved across sections. Standard chunking methods often miss these links, leading to incomplete or misleading answers.
Hard to Scale with Growing Content. As document collections grow, matching queries against large vector stores becomes slower and more expensive. This is especially challenging in domains where context and precision matter most.
HybridRAG's Transformatory Approach
HybridRAG redefines the RAG architecture by shifting from real-time generation to offline QA pre-generation. It builds a domain-specific QA knowledge base from PDFs and uses embedding-based semantic matching at inference to respond rapidly.
RAG Limitations and HybridRAG's Enhancements
Traditional RAG systems suffer from several critical limitations in document QA. Their reliance on runtime retrieval and LLM inference results in high latency and operational cost. Context fragmentation is common due to flat, paragraph-level chunking that fails with complex layouts like financial tables or technical diagrams. Additionally, standard vector search often retrieves irrelevant or semantically weak passages, leading to hallucinated or incomplete answers.
HybridRAG addresses these issues through architectural innovations and content-aware processing. It uses offline QA pre-generation, eliminating the need for live LLM inference on most queries. Its pipeline includes layout-based chunking (via MinerU), hierarchical RAPTOR-inspired segmentation, and visual element interpretation with GPT-4o. These enable deep semantic representation and structured QA mapping.
It also incorporates domain-specific visual reasoning by interpreting tables and figures into natural language, which is essential for domains like finance and administration where structured visual data dominates.
How HybridRAG Works
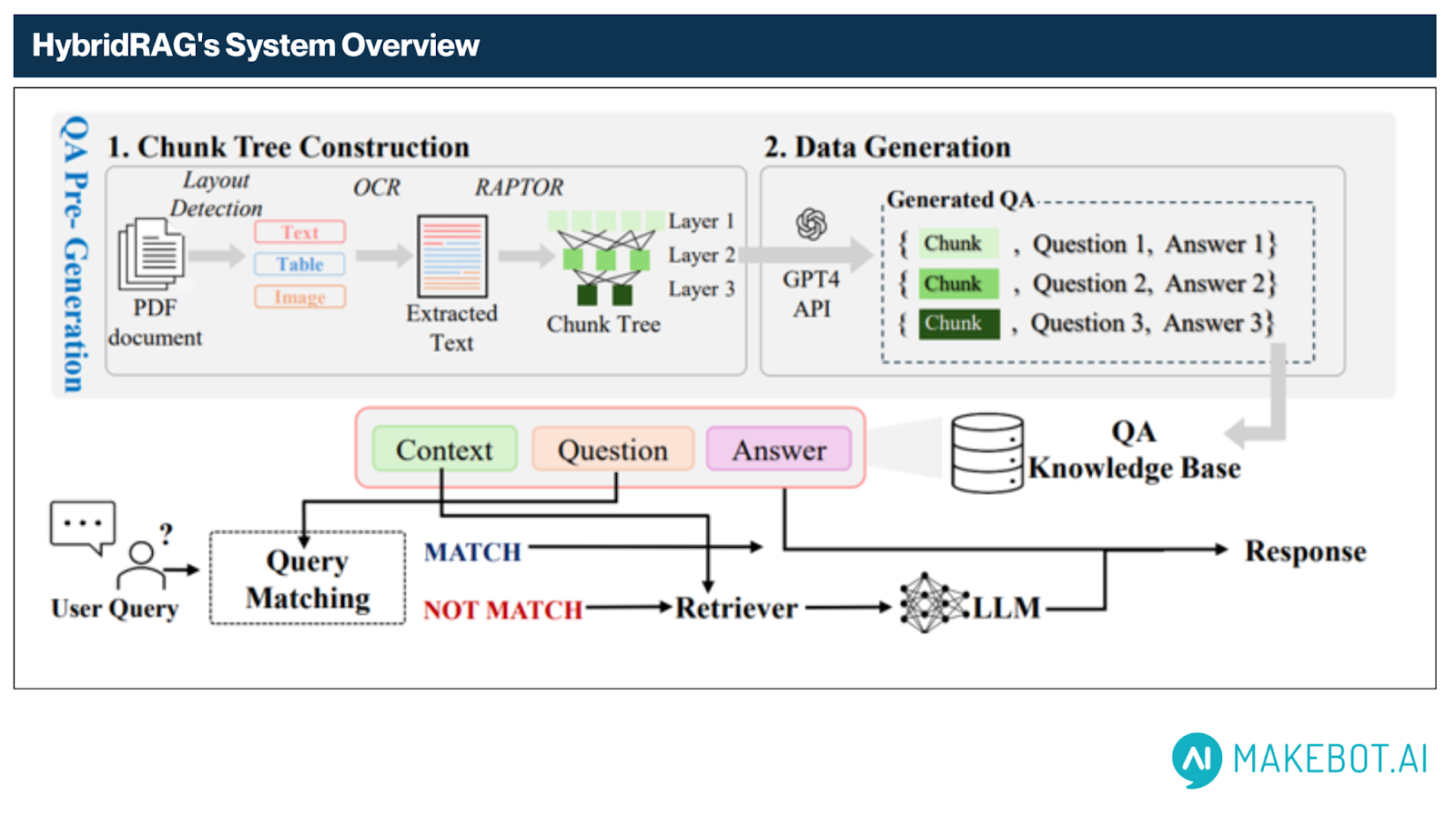
HybridRAG functions through a two-phase pipeline—Offline QA Pre-Generation and Online Query-Time Matching—that together form a highly optimized architecture for low-latency, high-quality question answering over complex, unstructured documents such as PDFs.
A. Offline Phase – QA Pre-Generation
This phase transforms raw PDF documents into a semantically rich QA knowledge base through structured document analysis and LLM-assisted QA generation. It consists of two primary stages as depicted in the diagram: Chunk Tree Construction and Data Generation.
We generate 15 QA pairs per page and at least 3 QAs even for small 200-token RAPTOR root nodes, ensuring dense semantic coverage.
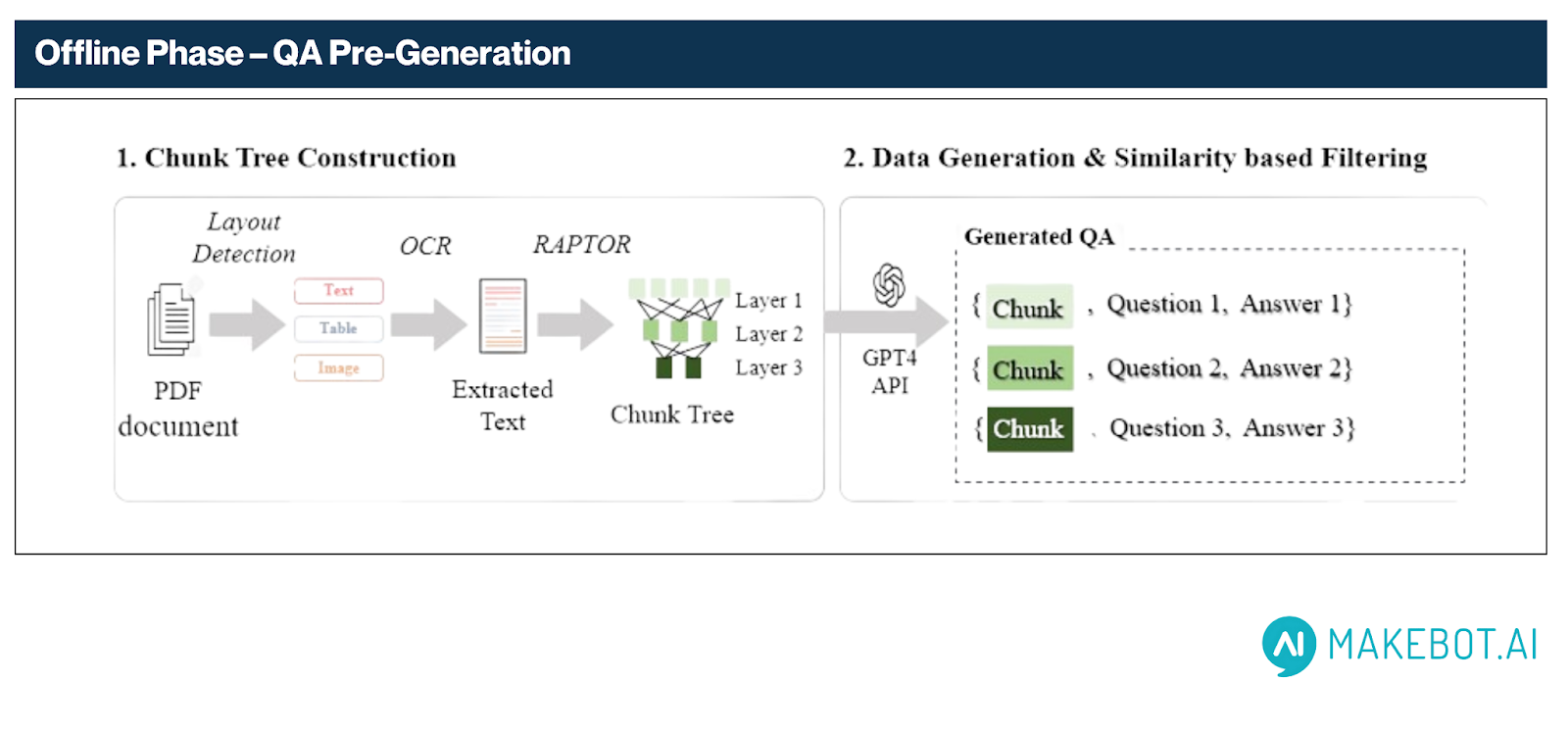
1. Chunk Tree Construction
- Layout-Aware Parsing: Using MinerU, the system first detects layout elements such as text blocks, tables, and figures in scanned PDFs. For visual elements (e.g., tables and charts), GPT-4o is used to generate natural language descriptions, improving downstream answerability.
- OCR Extraction: PaddleOCR extracts clean textual content even from irregular layouts—handling multi-columns, embedded fonts, and poor scan quality.
- Hierarchical Chunking via RAPTOR:
Inspired by the RAPTOR framework, HybridRAG recursively organizes content into a semantic chunk tree:- Higher nodes contain broad summaries and thematic context.
- Lower nodes retain fine-grained, paragraph-level detail.
2. Data Generation
- Adaptive Keyword Extraction: Each chunk is analyzed with GPT-4o-mini to extract keywords. Higher-level chunks receive more keywords due to their semantic richness, while leaf nodes receive fewer, targeted terms.
- Chain-of-Thought QA Generation:
For each keyword, GPT-4o-mini generates one QA pair using a structured reasoning approach. This ensures:- Coverage of diverse content
- Self-contained, contextually grounded questions
- QA counts per chunk aligned with content importance
B. Online Phase – Query Matching & Response Generation
Once the QA base is constructed, the system enters real-time operational mode. Here’s how it responds to user queries:
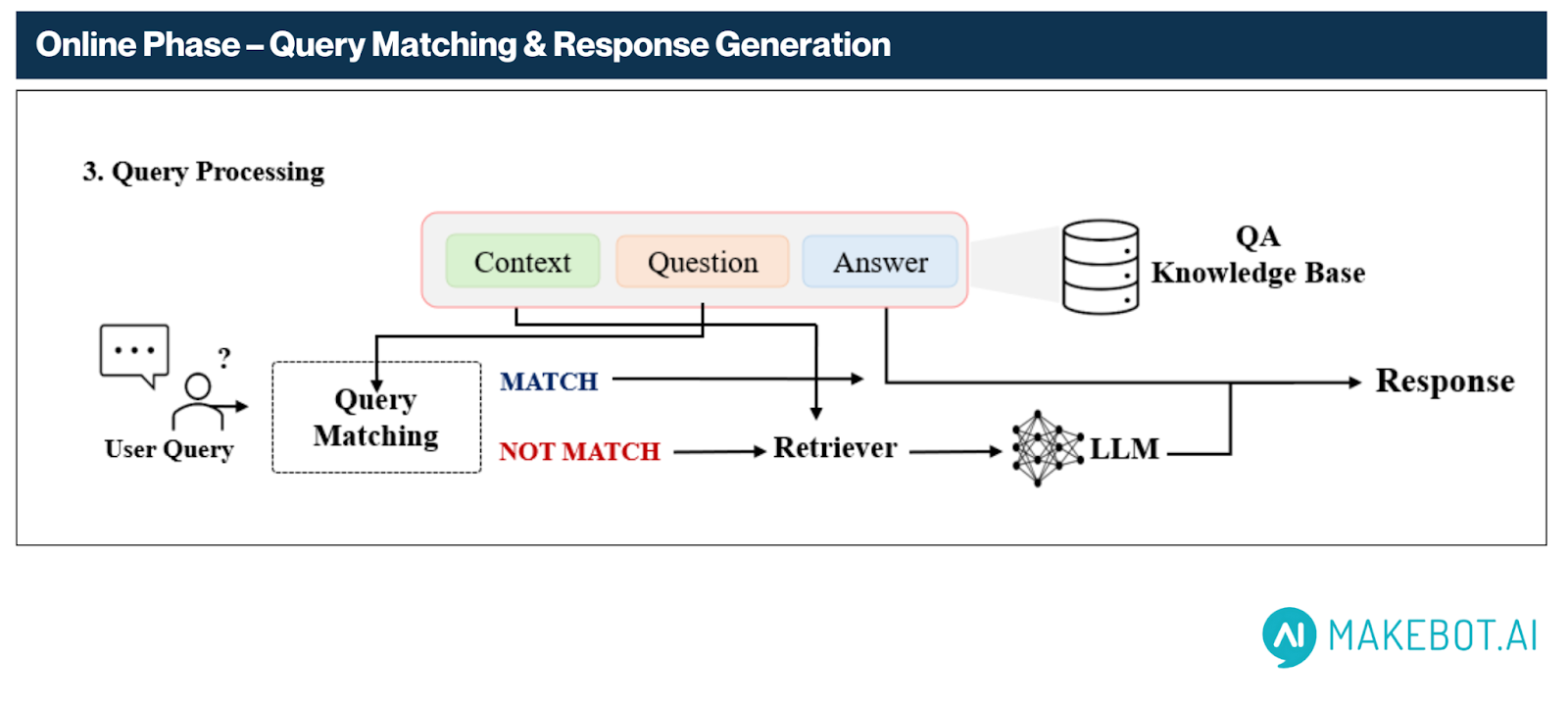
1. Query Matching via Semantic Embedding
- The user’s question is embedded using BGE-M3, and similarity is computed against all pre-generated questions in the QA base.
- If the top similarity score exceeds a configured threshold (e.g., 0.9), the corresponding pre-generated answer is returned directly.
2. Fallback Mechanism – Retriever + Generator
If no strong match is found:
- The system retrieves the top-3 closest QA pairs and aggregates their associated document chunks.
- These chunks, plus the associated questions, are sent to the LLM for real-time answer generation.
- Our experiments showed that including the retrieved questions improves performance, validating our QA-based retrieval strategy.
C. Response Output
The system returns the final response through one of two paths:
- Direct Match Path : Retrieved directly from QA Knowledge Base without LLM invocation.
- Fallback Generation Path : Generated via LLM using relevant context if no high-confidence match exists.
Optimization & Trade-offs
Balancing Cost, Speed, and Quality
HybridRAG is designed to optimize system performance across three critical dimensions: cost-efficiency, low latency, and answer quality. By leveraging offline QA generation and configurable semantic matching thresholds, it minimizes reliance on real-time LLM inference while maintaining high answer fidelity across complex document types.
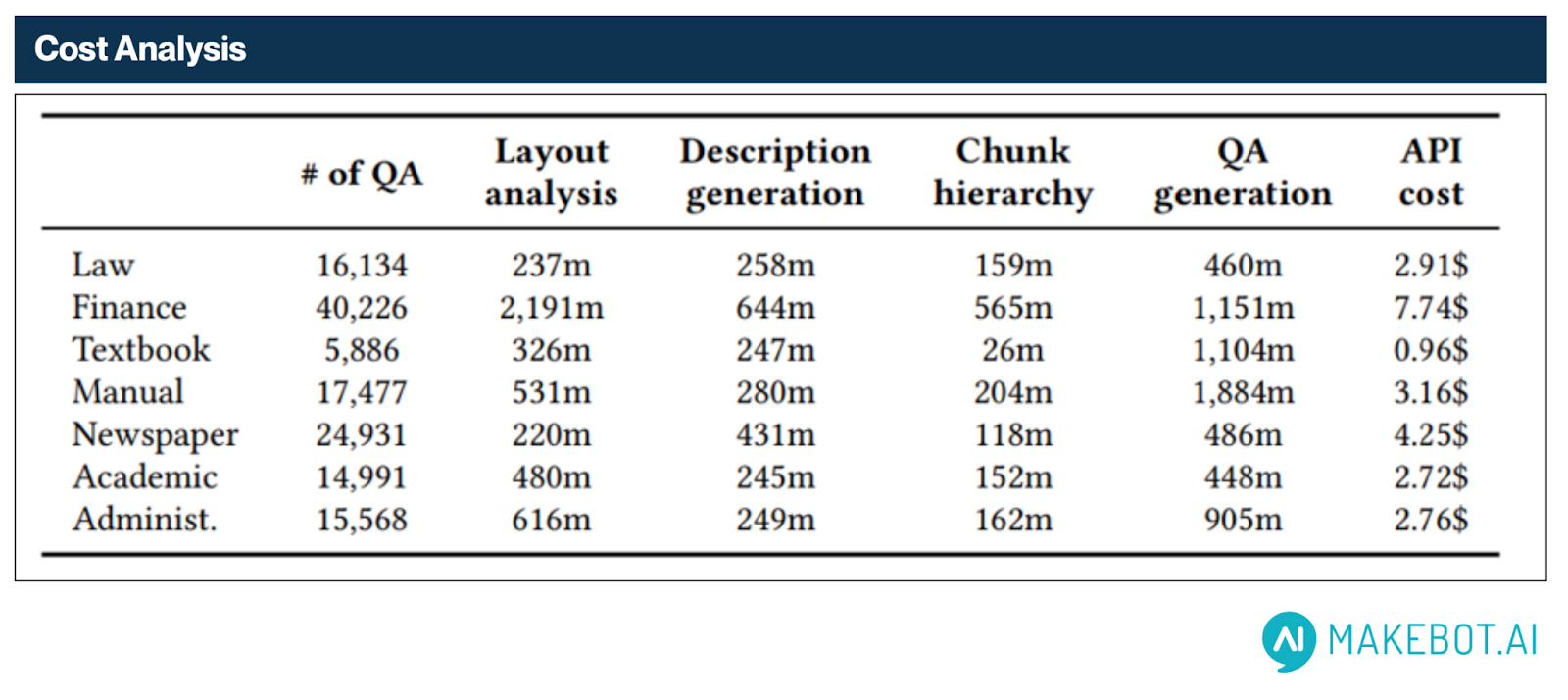
Cost-Effectiveness at Scale
HybridRAG minimizes operational costs by shifting the bulk of LLM usage to a one-time offline phase. Instead of querying the model in real time, it pre-generates over 130,000 QA pairs from diverse document sets across seven domains.
We generated 130,000 QA pairs across seven domains for only $24.50—averaging ~0.018¢ per QA pair.
Pre-generation stats:
- Total cost: $24.50
- Average per QA pair: ~0.018–0.019¢
- Examples:
- Finance: 40,226 QA pairs for $7.74
- Law: 16,134 QA pairs for $2.91
- Academic: 14,991 QA pairs for $2.72
This cost-efficient design allows HybridRAG to support high-throughput environments without incurring the high runtime expense of traditional LLM-based systems.
Threshold Tuning: Accuracy vs. Coverage
HybridRAG uses semantic similarity thresholds to decide when to return a pre-generated answer versus triggering the LLM fallback. A comprehensive threshold analysis revealed clear trade-offs:
- Threshold 0.9:
- Only 13% of queries use direct QA matches
- Higher LLM fallback rate → better quality, but increased latency
- Threshold 0.7:
- Enables 80% of queries to be served instantly via pre-generated answers
- Results in lower latency, but with reduced answer precision
Lower thresholds prioritize speed and throughput; higher thresholds optimize for factual quality and answer reliability.
Recommendation
- Use high thresholds (e.g., 0.9) for domains requiring precision and compliance (e.g., finance, legal).
- Use lower thresholds (e.g., 0.7) for user-facing applications where speed and coverage are more critical (e.g., support chatbots).
- We recommend dynamic thresholding based on domain or query type to maximize utility.
How HybridRAG Performs
We conducted comprehensive experiments using the OHRBench benchmark, consisting of 1,261 real-world PDF documents and 8,498 validated QA pairs across 7 diverse domains: Law, Finance, Textbook, Manual, Newspaper, Academic, and Administration.
The QA pairs were rigorously filtered from 15,317 candidates using criteria like RAG compatibility and correctness.
Comparison Baselines
- Standard RAG: No pre-generation, flat OCR-based chunking.
- Simplified HybridRAG: Pre-generates QA pairs but without layout parsing or hierarchical chunking.
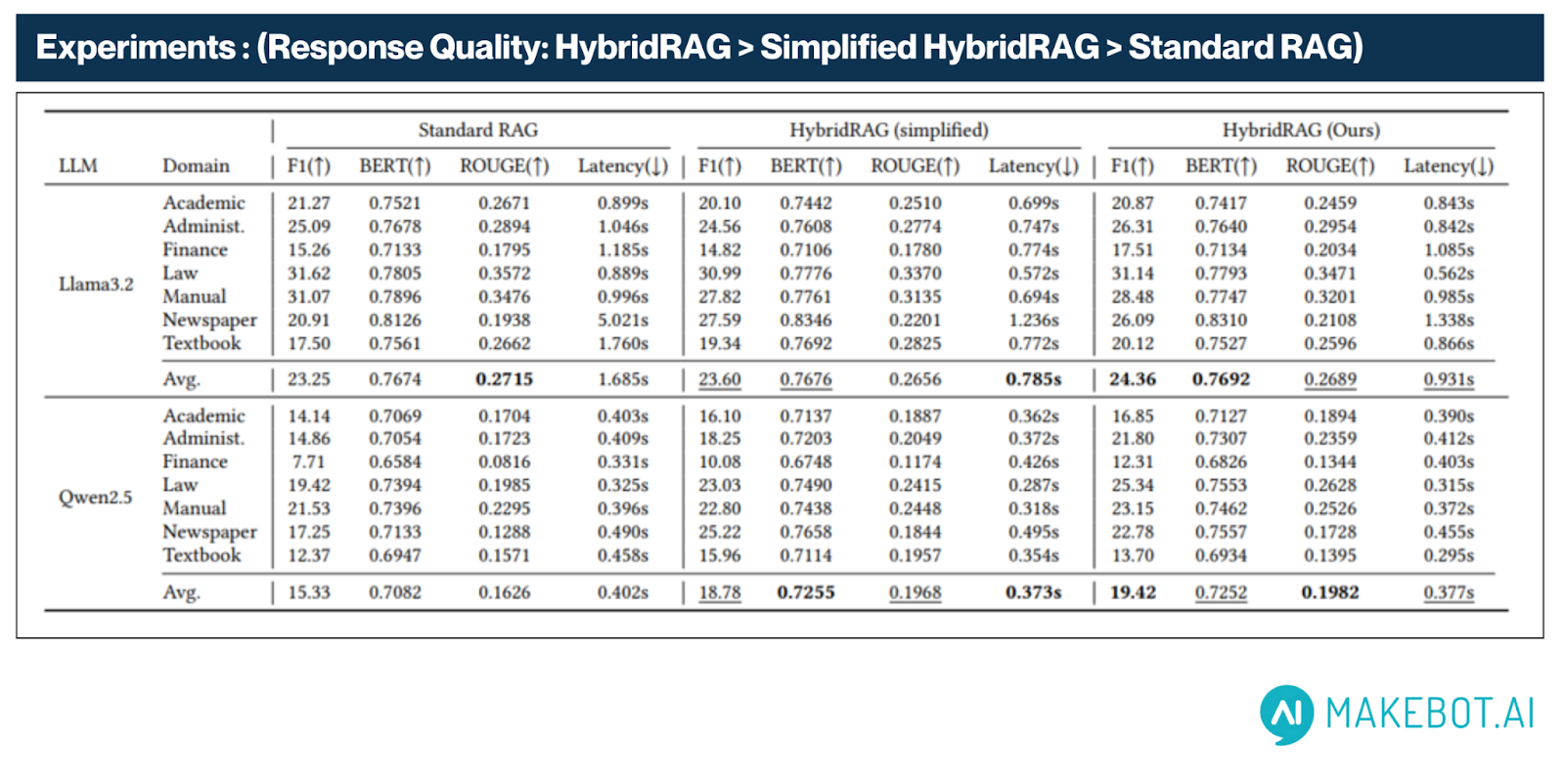
Quantitative Performance Metrics
Across both LLaMA3 and Qwen2.5 LLM backbones, HybridRAG consistently demonstrates superior performance compared to Standard and Simplified RAG systems, achieving gains in accuracy, semantic quality, and latency.
- F1 Score rose from 15.33 (Standard RAG) to 19.42 (HybridRAG), marking a 26.6% relative increase. This improvement reflects enhanced answer correctness and contextual precision across diverse document types.
- Under the LLaMA3.2 configuration, HybridRAG achieved an average F1 score of 24.36, compared to 23.25 in Standard RAG—indicating that even stronger backbones benefit from HybridRAG’s design.
- Under the LLaMA3.2 configuration, HybridRAG achieved an average F1 score of 24.36, compared to 23.25 in Standard RAG—indicating that even stronger backbones benefit from HybridRAG’s design.
- ROUGE improved from 0.1626 to 0.1982, capturing better n-gram and lexical overlap with reference answers—crucial for tasks involving technical or structured responses.
- BERT increased from 0.7082 to 0.7252, showing improved semantic alignment between system-generated answers and ground-truth labels. Notably, LLaMA3.2 consistently exhibited higher BERT values (e.g., 0.7692 in HybridRAG vs. 0.7674 in Standard RAG), emphasizing HybridRAG’s capability to amplify semantic coherence regardless of model.
- Latency dropped from 0.402 seconds (Standard RAG) to 0.377 seconds (HybridRAG) on average—representing a 6.2% reduction in response time, even with the addition of semantic matching and fallback mechanisms. With LLaMA3.2, HybridRAG maintained a latency of 0.931s, outperforming the 1.685s baseline.
- Latency tests conducted on NVIDIA RTX 3090 confirmed faster performance even with powerful models like LLaMA3.2.
These consistent gains across both (LLaMA3.2) and (Qwen2.5) LLMs reinforce HybridRAG’s model-agnostic performance advantage. Whether deployed with large or resource-efficient models, HybridRAG delivers faster, more accurate, and contextually aware responses—suitable for production-grade, enterprise-scale document QA systems.
Qualitative QA Evaluation (G-Eval)
Using an LLM-based evaluation framework (G-Eval), HybridRAG’s pre-generated QA outputs were benchmarked against human-annotated references from OHRBench.
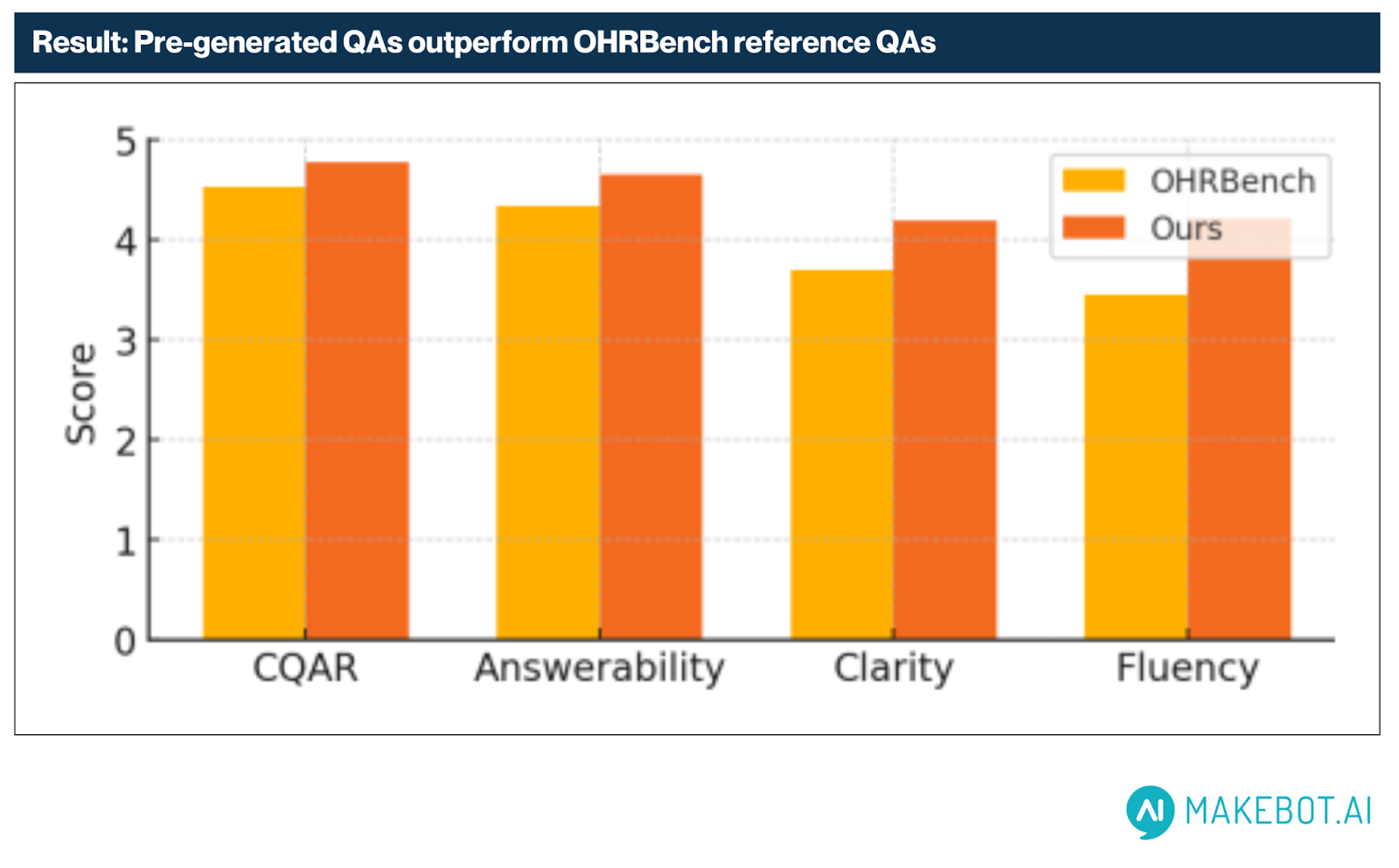
Results showed consistent superiority across all measured dimensions:
- Fluency: +0.76 (highest gain)
- Clarity: +0.50
- Answerability: +0.31
- Contextual QA Relevance (CQAR): +0.24
These gains affirm the effectiveness of HybridRAG’s Chain-of-Thought prompting and keyword-guided QA generation in producing human-like, high-fidelity outputs.
Strategic Framing, Leadership & Branding
A Vision Led by Jiwoong Kim
The groundbreaking research on HybridRAG: A Practical LLM-based ChatBot Framework was initiated, patented, and led by Jiwoong Kim, CEO of Makebot. As both the strategic leader and technical architect, Jiwoong Kim has uniquely blended visionary leadership with deep technical expertise to drive Makebot’s innovations in large language models (LLM) and retrieval-augmented generation (RAG) technologies.
Jiwoong connects leadership with real technical action. Under his guidance, Makebot’s work powered real business solutions across Korea. His leadership has earned national recognition for Makebot as the country’s foremost force in LLM and RAG, highlighted by its showcase at SIGIR 2025—the globe’s top conference in information retrieval research.
Putting Korea on the Global AI Map
But it’s not just technology for technology’s sake. Jiwoong is equally passionate about practical impact. His laser focus is on creating tools that truly serve people—helping organizations and customers connect smarter and more naturally.

In Jiwoong’s Words
“Our aim isn’t theoretical progress. We’re here to solve real challenges, making sure AI delivers concrete value in daily life” Jiwoong explains. This practical, solution-driven mindset keeps Makebot at the forefront of AI.
Why This Matters for Korea and the Global AI Community
The ACM SIGIR conference remains the world’s premier venue for cutting-edge research and innovation in information retrieval. Makebot’s participation in SIGIR 2025, with the presentation of HybridRAG, marks Korea’s rising influence and growing leadership in the global AI field.
Korea is no longer just participating, it’s defining the conversation. Makebot’s work with LLM and retrieval-augmented generation is a national success story—one that blends deep research, smart problem-solving, and real technical impact. HybridRAG is engineered to deliver real business value through innovative and faster ways of handling raw and unstructured data.
We’re just getting started. The drive to push LLM and RAG technology further is in full swing, and the pace isn’t slowing down.
Follow Makebot.ai for more research, expansion, and significant moments in the field of AI. Stay tuned to see where intelligent information retrieval is headed next. The story is still being written.

.jpg)




































.jpg)

.png)




















































_2.png)



