From Pilot to Production: How Enterprises Can Successfully Scale LLM Chatbots Across the Organization
From pilot to production: how enterprises scale LLM chatbots with data, governance, and ROI!


Modern enterprises are racing toward an AI-enabled future—but few cross the finish line. The majority of organizations can launch a proof-of-concept for LLM Chatbots, yet only a small fraction manage to turn these early wins into full-scale, enterprise-wide systems that deliver real ROI. Industry research consistently shows a stark mismatch: while Generative AI adoption is accelerating, more than 45.9% of enterprises still struggle to scale these systems beyond isolated experiments.
In reality, scaling Enterprise AI is less about algorithms and more about architecture, governance, and organizational discipline. Pilots are easy—production is hard. This article breaks down what the data, the research, and real-world deployments reveal: how enterprises can turn prototypes into reliable, governed, secure AI capabilities embedded across every function.
And it begins with a mindset shift—treat scaling not as a technical milestone, but as an operational transformation.
Why Most Enterprise Chatbot Projects Fail Before They Begin. Read more here!

Start with Enterprise Strategy, Not Technology
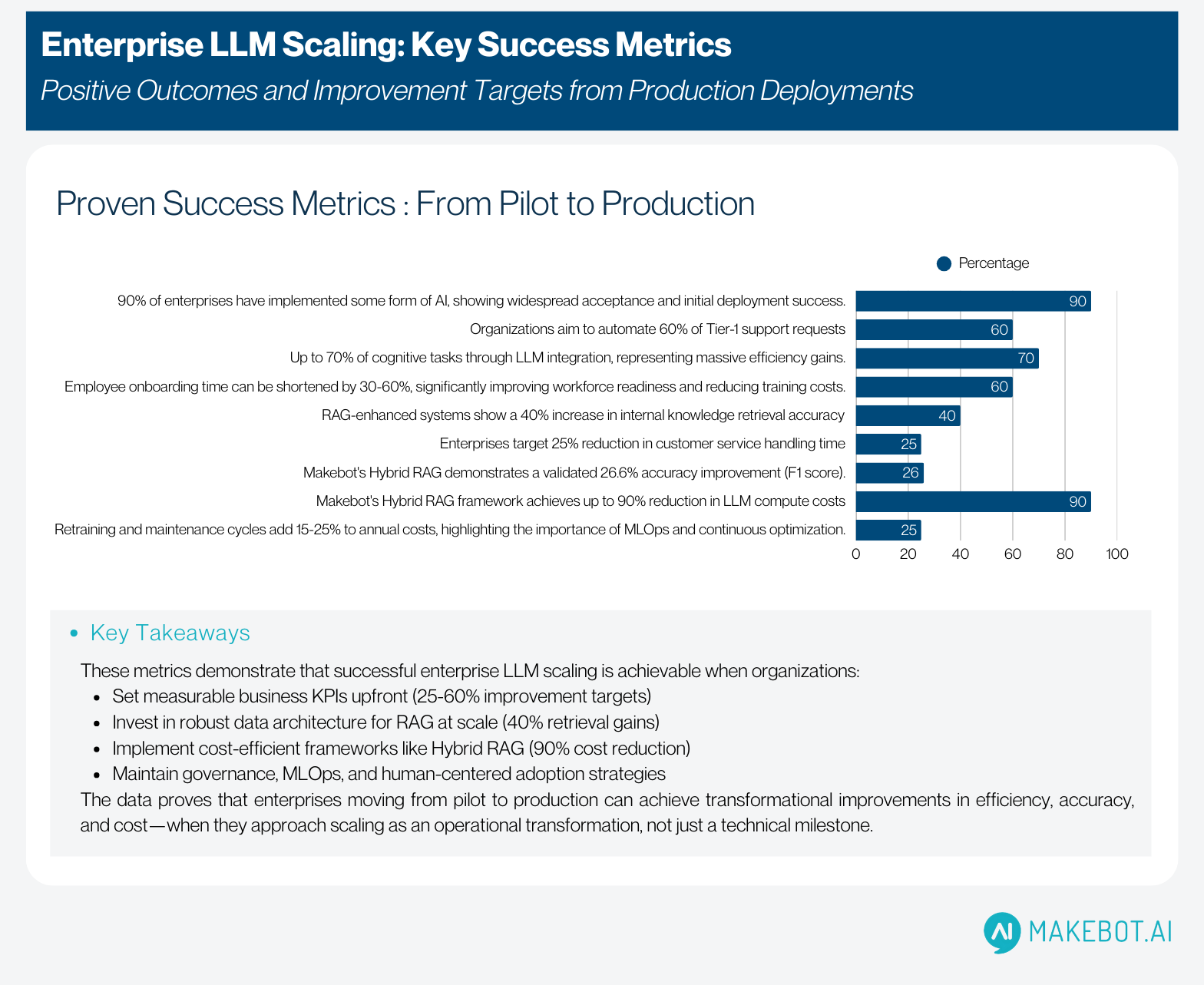
Before an enterprise can scale LLM Chatbots, it must define why they exist. This seems simple, yet most failures trace back to unclear problem statements and metrics. Research shows that although 90% of enterprises already use some form of Enterprise AI, only a minority tie their initiatives to real business KPIs.
When leaders jump directly into models, vendors, or feature lists, pilots succeed technically but fail organizationally—because no one can prove business impact.
The enterprises that scale successfully do three things:
A. Define measurable business outcomes upfront
Examples include:
- Reduce customer-service handling time by 25%
- Increase internal knowledge retrieval accuracy by 40%
- Automate and handle 60% of Tier-1 requests
- Shorten employee onboarding by 30-60%
These KPIs give direction to engineering teams and cover the entire lifecycle—from architecture to governance and ongoing optimization.
B. Tie chatbot capabilities to cross-functional workflows
Successful enterprises do not ask: Where can we use AI?
They ask: “How would this function operate if 60% of cognitive tasks were automated by an LLM?”
C. Align scaling strategy with executive sponsorship
Scaling requires budget continuity, roadmap consistency, and cultural adoption—all driven top-down.
This strategic grounding leads naturally to the next challenge: data.
Build a Data Architecture Designed for RAG at Scale
LLM performance in production is less about model intelligence and entirely about data readiness. In fact, 62.9% of enterprises cite data quality, data fragmentation, or data access constraints as their biggest barrier to scaling Generative AI.
Most enterprises underestimate this step by a factor of three.
To scale beyond pilots, organizations must create a robust Retrieval-Augmented Generation (RAG) pipeline that transforms scattered, unstructured data into consistent, governed, version-controlled knowledge.
A. Normalize and structure your enterprise content
Enterprise knowledge often exists across:
- PDFs with inconsistent layouts
- Outdated policies in SharePoint
- CRM notes with missing metadata
- Department-specific repositories
As highlighted , 80% of all AI project time is spent on data preparation—from normalization to metadata enrichment.
B. Build scalable retrieval layers
A scalable RAG architecture requires:
- Chunking optimized for semantic meaning
- Embedding pipelines with uniform taxonomies
- Vector databases supporting versioning, security, and role-based access
- Automated document updates as policies evolve
C. Governance built into the data pipeline
This includes:
- Data lineage tracking
- Access controls per department
- Approved source prioritization
- Bias and hallucination mitigation
Enterprises that implement these foundations see major accuracy improvements—long before model tuning even begins.
With data ready, the next barrier emerges: Systems Integration.
Solve Integration Early: The Hidden Gatekeeper of Scale
Scaling LLM Chatbots across an enterprise requires deep integration with CRMs, ERPs, HRIS platforms, knowledge graphs, identity systems, and more.
This is where most pilots die.
Industry research confirms: 30–40% of the AI budget is consumed by integration and maintenance, not the model itself.
A. Architect for modularity, not monoliths
Successful enterprises separate:
- The LLM service
- The API/action layer
- Tooling connectors
- Business logic
- Guardrail systems
- Audit and monitoring layers
This modularity supports multi-department scaling without rewriting the core system.
B. Introduce an orchestration layer for agentic workflows
As organizations evolve toward semi-autonomous, multi-step agents, they require an AI orchestration fabric capable of:
- Context management
- Tool invocation
- Memory handling
- Multi-agent coordination
The source highlights that enterprise implementations increasingly rely on hybrid architectures—combining proprietary APIs and open-source checkpoints to reduce costs and increase control.
C. Build once, integrate everywhere
A scalable integration layer must support:
- Slack, Teams, Web, Mobile
- Internal portals (HR, IT, Finance, Ops)
- External channels (WhatsApp, SMS, Webchat)
This ensures the chatbot becomes an organizational platform, not a siloed tool.
But integrations are only part of the story. The next barrier is trust.
Operationalize Governance: The Foundation of Enterprise Reliability
An enterprise cannot scale without trust—legal, operational, and reputational. AI governance weaknesses are the #1 reason enterprises halt rollout plans mid-stream.
According to enterprise studies, over 60% of organizations cite governance, compliance, and safety risk as barriers to Generative AI adoption.
To scale safely, enterprises must enforce multi-layered governance:
A. Guardrails at the model layer
- Temperature control
- Response-length limits
- Restricted vocabulary for regulated outputs
B. Guardrails at the retrieval layer
- Only approved documents can ground responses
- Real-time grounding checks
- Retrieval validation before generation
C. Guardrails at the action layer
- Strict policies for CRM updates
- Transaction validation before execution
- Human approval for high-risk actions
D. Continuous auditing
Enterprises must maintain:
- Log-level traceability
- Hallucination detection pipelines
- Bias audits across departments
- Version-controlled model deployments
Without governance, enterprises create “shadow AI”—systems that work until they fail catastrophically. With governance, enterprises unlock a safe scale.
And governance enables the next barrier to be addressed: Human Adoption.
Build a Human-Centered Operating Model for AI
Scaling Enterprise AI is not an engineering challenge—it is a cultural one. Highly successful deployments share one characteristic: humans understand when and how to collaborate with AI systems.
Research shows that organizations see the highest productivity gains when LLMs act as accelerators rather than replacements.
To enable this shift, enterprises must invest in:
A. Role Redesign
Every department needs new AI-augmented workflows:
- Agents become validators instead of answer generators
- Analysts become auditors instead of manual synthesizers
- Managers become orchestrators of automated workflows
B. Training programs that build AI literacy
Teams must learn:
- How to judge LLM outputs
- How to correct hallucinations
- How to escalate edge cases
- How to maintain accuracy feedback loops
C. Transparent communication to reduce resistance
Fear-based cultures stall AI rollouts. Outcome-based cultures accelerate them.
This human alignment opens the door to true enterprise-scale performance.
Beyond the Build: Uncovering the Hidden Costs of In-House LLM Chatbot Development. More here!
Implement MLOps & AI Operations for Enterprise-Grade Scaling
Without strong AI Operations, LLM Chatbots degrade quickly and unpredictably.
Industry data shows:
- LLM performance drifts within 30–90 days
- 74% of enterprises underestimate post-deployment maintenance needs
- Retraining cycles add 15–25% of annual cost
Scaling requires an industrialized AI Development pipeline:
A. Automated evaluation frameworks
- Accuracy benchmarks
- Guardrail stress tests
- Prompt regression testing
- Retrieval performance scoring
B. Continuous optimization pipelines
- Re-indexing vector stores
- Updating content as documents change
- Prompt and parameter optimization
- Hybrid model routing to reduce costs
C. Cost-aware routing architectures
As highlighted in your previous article, LLM inference cost can increase 8–12x from PoC to production. Enterprises need:
- Lightweight model routing
- Caching systems
- Offline QA generation (HybridRAG)
- Multi-model escalation frameworks
With MLOps in place, enterprises can finally scale their systems sustainably.
Expand from Use Case to Ecosystem: The Enterprise Scaling Blueprint
To scale across the organization, enterprises must shift from chatbot deployment to platform thinking.
Phase 1 — Foundation
- Define KPIs
- Prepare data pipelines
- Build governance
- Create an AI orchestration layer
Phase 2 — Department Rollouts
- Customer support
- HR self-service
- IT operations
- Sales and field enablement
- Finance/Procurement assistants
Each rollout strengthens the enterprise AI mesh.
Phase 3 — Cross-Functional AI Applications
- Autonomous case routing
- Multi-step agentic workflows
- Organization-wide semantic search
- Cross-system automation
Phase 4 — Enterprise AI Ecosystem
At maturity, enterprises operate with a unified AI stack that:
- Connects all workflows
- Grounds all decisions in shared data
- Enables any employee to query organizational knowledge
- Ensures governance across departments
- Scales new LLMs and tools seamlessly
This is where real competitive differentiation emerges.
Makebot: Turning Scalable LLM Deployment into Reality
While many enterprises struggle to scale LLM Chatbots past the pilot stage, Makebot provides a proven blueprint for production-ready Enterprise AI. Its patented HybridRAG™ framework—recently showcased at SIGIR 2025 in Padua, Italy—demonstrates how Korea is shaping the global future of practical, high-performance AI systems.
HybridRAG™: Built for Real Enterprise Scale
Unlike traditional RAG pipelines that rely on expensive, real-time LLM inference, HybridRAG shifts intelligence offline by pre-generating dense QA knowledge bases from complex PDFs and unstructured documents. At runtime, the chatbot answers queries instantly using semantic matching—invoking an LLM only when necessary.
The result:
- Up to 90% reduction in LLM compute costs
- 26.6% improvement in accuracy (F1)
- Faster response times, even with messy layouts, tables, and structured documents
- Scalable, compliant, and model-agnostic deployment
HybridRAG’s efficiency was validated through 130,000 QA pairs generated across seven domains for only $24.50—a powerful demonstration of sustainable AI scaling.
Leadership That Connects Research to Deployment
HybridRAG was invented and patented by Jiwoong Kim, CEO of Makebot, whose vision bridges academic rigor with enterprise practicality. His work positions Makebot as a national leader in Generative AI, with deployments across hospitals, government agencies, universities, and major enterprises in Korea.
Why Makebot Matters for Enterprise Scaling
For organizations struggling with the pilot-to-production gap, Makebot offers what most ecosystems lack:
- A cost-efficient, production-ready RAG architecture
- Governance-by-design with auditability and accuracy controls
- Enterprise platforms (BotGrade, MagicTalk, MagicSearch) for rapid rollout
- Domain-specific LLM agents built for healthcare, finance, education, logistics, and government
Makebot proves that scaling LLM Chatbots is not just possible—it is achievable today with the right architecture, governance, and operational discipline.
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy. More here!
Conclusion
Enterprises that succeed with LLM Chatbots don’t win because they have better models. They win because they have better systems—better data, better governance, better integration, and better cultural alignment.
To scale Generative AI from pilot to production, enterprises must:
- Treat AI as business transformation, not an IT project.
- Invest early in data pipelines and retrieval architectures.
- Build robust governance systems before deployment.
- Integrate LLM capabilities deeply into operational workflows.
- Maintain continuous optimization via MLOps and AI operations.
- Enable human teams to thrive alongside automated intelligence.
The future belongs to enterprises that build Enterprise AI ecosystems—not one-off experiments.
And for organizations ready to operationalize at scale, one partner already specializes in eliminating the pilot-to-production gap.
Scale LLM Chatbots with Confidence
Makebot helps enterprises move beyond pilots by delivering production-ready LLM and Generative AI solutions built for accuracy, governance, and cost efficiency. With patented HybridRAG™, industry-specific LLM agents, and deployment frameworks trusted by over 1,000 Korean enterprises, Makebot accelerates AI scaling across every department.
Whether you need secure integrations, enterprise-grade governance, or end-to-end AI Development, Makebot transforms your chatbot strategy into measurable results—fast.
👉 Begin your AI transformation today: www.makebot.ai
📩 Contact us: b2b@makebot.ai































.jpg)

.png)




















































_2.png)