LLMs as Clinical Co-Pilots (Not Decision Makers)
Clinical AI delivers value only when human accountability defines decisions, boundaries, and risk.


Why the “Co-Pilot” Model Matters in Modern Medicine
The rapid rise of AI in healthcare has reignited a long-standing debate: should artificial intelligence assist clinicians, or should it replace elements of clinical judgment altogether? As Large Language Models continue to demonstrate impressive reasoning and language capabilities, the answer emerging from real-world clinical evidence is increasingly clear—LLMs are most effective when positioned as clinical co-pilots, not autonomous decision makers.
This distinction is not philosophical; it is operational, ethical, and patient-safety critical. Recent prospective clinical studies show that when an LLM collaborates with trained healthcare professionals, performance improves measurably. When deployed alone, however, limitations become evident—especially in complex, high-risk medical decisions.
Key Healthcare AI Trends Shaping Innovation in 2026. Read more here!
Glossary of Key Terms
Clinical Co-Pilot . An AI-assisted model where LLMs work alongside clinicians to reduce cognitive load, surface risks, and improve consistency, while final responsibility remains human-led.
Clinical Decision Maker . A licensed healthcare professional who evaluates evidence, applies clinical judgment, and assumes legal and ethical accountability for patient care.
Retrieval-Augmented Generation (RAG) . A method that grounds LLM outputs in external knowledge sources to improve relevance and transparency, without eliminating the need for human oversight.
Automation Bias . The tendency to over-trust AI recommendations, reinforcing the importance of framing LLMs as assistive tools rather than authoritative systems.
Human-in-the-Loop (HITL). An operational AI model in which Large Language Models perform analysis, reasoning, and recommendation generation, while final judgment, accountability, and action remain explicitly with human experts. HITL is a foundational requirement for deploying Generative AI in high-risk, high-regulation environments such as healthcare, finance, and the public sector, where error costs and ethical responsibility cannot be automated.
From Rule-Based Alerts to Reasoning Systems
The Limits of Traditional Clinical Decision Support
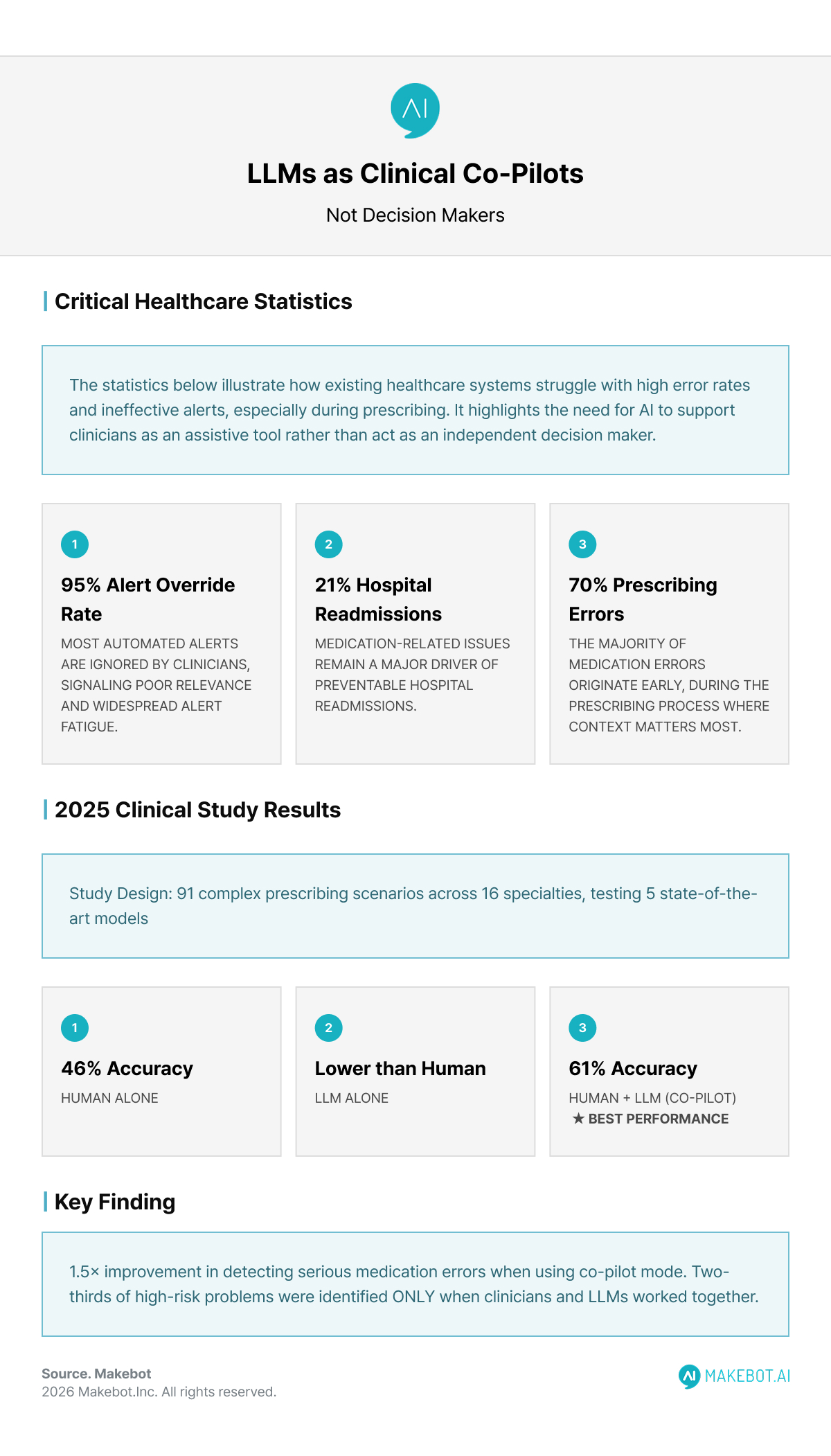
Conventional clinical decision support systems (CDSS) are largely rule-based. While effective in narrow contexts—such as flagging basic drug-drug interactions—they often generate excessive, low-relevance alerts. Studies report alert override rates as high as 95%, a phenomenon widely known as alert fatigue. This not only diminishes clinical trust but can paradoxically increase patient risk.
Medication-related errors remain one of the most persistent challenges in healthcare, accounting for roughly 21% of hospital readmissions, with nearly 70% occurring at the prescribing stage. The global economic burden runs into tens of billions of dollars annually.
Why Generative AI Changes the Equation
Unlike static rule engines, Generative AI—particularly LLM-based systems—can reason over unstructured clinical notes, lab data, medication histories, and contextual patient factors. Rather than issuing binary alerts, these systems synthesize information and generate natural-language explanations, aligning more closely with how clinicians actually think.
This capability has positioned the AI Chatbot interface as a powerful front end for clinical reasoning support—if used correctly.
Evidence from Real Clinical Workflows
LLMs in Medication Safety: What the Data Shows
A 2025 prospective, cross-over study evaluated LLM-based CDSS tools across 16 medical and surgical specialties, using 91 complex prescribing error scenarios. Five state-of-the-art models—including GPT-4 variants, Gemini, and Claude—were tested under three configurations:
- Human clinician alone
- LLM alone
- Human + LLM (co-pilot model)
The results were decisive:
- Co-pilot mode achieved the highest accuracy (61%), outperforming both clinicians alone (46%) and LLMs alone
- Detection of potentially serious medication errors improved 1.5× in the co-pilot configuration
- Two-thirds of high-risk drug-related problems were identified only when clinicians and LLMs worked together
Critically, autonomous LLM performance lagged in nuanced tasks such as dosage adjustment—an area where local protocols, patient context, and clinician judgment remain indispensable.
10 Key LLM Market Trends for 2026. Read here!

Clinical Co-Pilot vs. Clinical Decision Maker
A Boundary That Must Be Preserved
The temptation to simplify AI medical diagnosis as an automation problem is strong. However, real clinical diagnosis is not a simple computational task—it is a process heavily dependent on probability and context.
While today’s LLMs possess impressive reasoning capabilities, they do not have situational awareness, agency of responsibility, or legal accountability.
Recently, some technology leaders have suggested that the combination of humanoid robots and AI could allow robots to outperform human surgeons in certain surgical domains. Elon Musk has publicly referenced such possibilities. In fact, in specific surgical areas requiring extreme precision and repeatability, robotic technologies have already surpassed human physical limitations.
However, this technological progress does not imply that AI should become the agent of clinical decision-making. If Musk’s statements concern the performance of surgical execution, the real question facing healthcare remains: who decides, and who bears responsibility?
At this intersection, medical AI is most realistically designed not as a replacement, but as a clinical co-pilot that augments human judgment.
Accordingly, the following distinction must remain clear:
- Clinical decision support involves surfacing risks, summarizing data, and presenting possible options
- Clinical decision-making involves accepting the consequences of choices, judging under uncertainty, and bearing final responsibility
The latter belongs exclusively to human clinicians. The value of using LLMs as clinical co-pilots is clear:
- They effectively reduce clinicians’ cognitive burden
- They surface risks that are easy to overlook
- They improve consistency across complex review processes
Governance, Safety, and Ethical Constraints
Transparency and Explainability
One advantage of conversational LLM interfaces over traditional black-box models is explainability. Clinicians can interrogate the system, request clarifications, and challenge recommendations—something impossible with static alerts.
However, explainability does not equal correctness. Even retrieval-augmented generation (RAG) systems showed no consistent accuracy gains in the referenced study, underscoring that grounding alone does not eliminate hallucinations or bias.
Automation Bias and Over-Trust
Multiple studies caution against automation bias—where clinicians defer to AI suggestions even when incorrect. This risk increases when systems are framed as authoritative rather than assistive. Clear UX design, training, and governance frameworks are essential to prevent over-reliance.
Regulatory Reality
From an enterprise and regulatory standpoint, fully autonomous AI systems face steep barriers. Accountability, auditability, and medico-legal responsibility remain unresolved. Co-pilot systems, by contrast, align more naturally with existing regulatory structures because humans remain the final decision authority.
Where AI Advancements Are Headed Next
The future of AI in healthcare is not autonomous diagnosis but augmented expertise. Emerging models with improved reasoning transparency, tighter domain grounding, and workflow-native integrations will further strengthen the co-pilot paradigm.
Likely near-term applications include:
- Pre-visit chart summarization
- Medication reconciliation screening
- Clinical documentation assistance
- Risk stratification support in understaffed settings
In low-resource environments, hybrid AI-first screening models may fill gaps—but even here, escalation to human oversight remains non-negotiable.
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy. Read here!
Conclusion: Augmentation Over Automation
The most compelling evidence to date supports a simple but powerful conclusion: LLMs deliver the greatest clinical value when they work with clinicians, not instead of them.
As Large Language Model technology continues to mature, healthcare leaders should resist the temptation of full automation and instead invest in thoughtfully designed co-pilot systems. These systems respect the complexity of medicine, preserve human accountability, and harness Generative AI where it performs best—enhancing safety, consistency, and clinical insight.
In healthcare, the future is not AI or clinicians.
It is clinicians—with AI.
Turning Clinical Co-Pilot Theory into Real-World Systems
In its recent analysis of 2026 LLM market trends, Makebot identified Human-in-the-Loop (HITL) as the standard operating model for enterprise AI. This reflects the recognition that in high-risk and highly regulated industries, AI must perform analysis and reasoning while final judgment and accountability remain human.
Makebot has applied these HITL principles across multiple LLM solutions and healthcare deployments. That experience converges on a single conclusion: healthcare AI competitiveness in 2026 will be defined not by the depth of automation, but by how safely human judgment can be augmented.
The clinical co-pilot is not merely a technical feature, but an operational philosophy that respects both the complexity of medicine and regulatory reality. The boundary of AI medical diagnosis should be drawn not at the limits of technology, but at the point where humans refuse to relinquish responsibility.
If you are exploring how to apply the clinical co-pilot model in real healthcare environments, Makebot welcomes further discussion.
👉 www.makebot.ai | 📩 b2b@makebot.ai



























.jpg)

.png)




















































_2.png)