
Stanford Develops Real-World Benchmarks for Healthcare AI Agents
Stanford sets real-world benchmarks to test healthcare AI agent safety.


The rapid expansion of Generative AI has created unprecedented momentum for AI in Healthcare, promising to automate clinical tasks, reduce administrative overload, and support clinicians facing severe staffing shortages. But in a domain where decisions directly affect patient safety, innovation cannot rely on hype or lab-only evaluations. Real-world performance—not theoretical capability—is what determines whether a system can be trusted inside hospital workflows.
This is the gap that Stanford University is now closing. With the creation of MedAgentBench, the first comprehensive benchmark designed to evaluate Healthcare AI Agents in realistic electronic health record (EHR) environments, Stanford is helping the industry distinguish between systems that merely sound intelligent and those capable of executing safe, reliable, clinically meaningful actions.
How Claude AI Is Transforming Clinical Research and Healthcare Innovation. Read more here!
Glossary of Key Terms
Healthcare AI Agents. Autonomous or semi-autonomous artificial intelligence systems capable of performing clinical or administrative tasks within healthcare environments. Unlike traditional chatbots, healthcare AI agents can execute multi-step workflows inside Electronic Health Record (EHR) systems, such as retrieving patient data, ordering labs, prescribing medications, and documenting care.
FHIR (Fast Healthcare Interoperability Resources). A global healthcare data standard developed by HL7 that enables secure and standardized exchange of medical information between systems. FHIR uses APIs (such as GET and POST requests) to allow interoperability between EHR platforms, applications, and AI agents.
Agentic AI. A class of AI systems designed not only to generate text or predictions, but to take structured actions within defined environments. In healthcare, agentic AI refers to models that can interact with clinical systems, execute workflows, call APIs, and perform task-based operations under safety constraints.
Human-in-the-Loop (HITL). A safety framework where AI systems operate under human supervision, requiring clinician review or approval before executing high-risk decisions. HITL ensures accountability, oversight, and regulatory compliance in sensitive domains such as healthcare.
Why the Healthcare Industry Needs Real-World Benchmarks Now
Even the most advanced Medical AI models historically excelled at medical exams and question-answering benchmarks. Systems like GPT-4, Claude, and Gemini consistently perform at near-expert levels on the USMLE, demonstrating strong reasoning and clinical knowledge.
But real clinical care is not a multiple-choice test. Physicians operate within messy workflows, fragmented data systems, time-sensitive decisions, and strict safety constraints. Their daily tasks involve multistep actions—retrieving records, ordering labs, prescribing medications, documenting care—each requiring precision and interoperability.
In short: Knowledge ≠ Task execution. Chat performance ≠ Clinical reliability.
Jonathan Chen, senior author of the MedAgentBench study, summarizes the difference clearly: “Chatbots say things. AI agents can do things.”
Until now, no benchmark existed to test whether AI agents could act, not just talk, within an EHR. Without such benchmarks, hospitals risk deploying unproven tools into high-stakes environments, where even a minor error—wrong dosage, incorrect patient, incomplete data retrieval—could have severe consequences.
Stanford’s benchmark directly confronts this challenge.

How Stanford Builds the First Real EHR Benchmark for Agentic Clinical AI
The MedAgentBench project is a multidisciplinary effort across Stanford University, involving physicians, computer scientists, and health informatics experts. Their design principle is simple but transformative: Test AI models inside a virtual EHR that mirrors real clinical workflows—not synthetic quizzes.
1. A Virtual EHR Built for Realistic Complexity
To replicate genuine hospital environments, the Stanford team constructed a FHIR-compliant EHR system with:
- 100 realistic patient profiles
- 785,000 clinical records, including labs, medications, diagnoses, vitals, imaging, and procedures
- Longitudinal, messy, and sometimes incomplete data—reflecting real-world data irregularities
This virtual EHR enables precise, reproducible testing of agent behavior under realistic conditions.
2. 300 Physician-Authored Clinical Tasks
Tasks were developed by licensed physicians and span 10 major clinical categories, such as:
- Retrieving structured patient data
- Reviewing lab trends and vital abnormalities
- Ordering imaging or tests
- Prescribing or adjusting medications
- Documenting findings
- Coordinating referrals or follow-ups
Most tasks include 2–3 step workflows, requiring proper use of FHIR API endpoints (GET, POST), correct data interpretation, and safe order execution.
3. Strict, Safety-Aligned Evaluation Metrics
Success rate is measured, meaning the agent must get the task right on the first attempt—mirroring real clinical safety expectations.
An orchestration layer limits each agent to eight interaction rounds and nine EHR functions, enforcing realistic constraints.
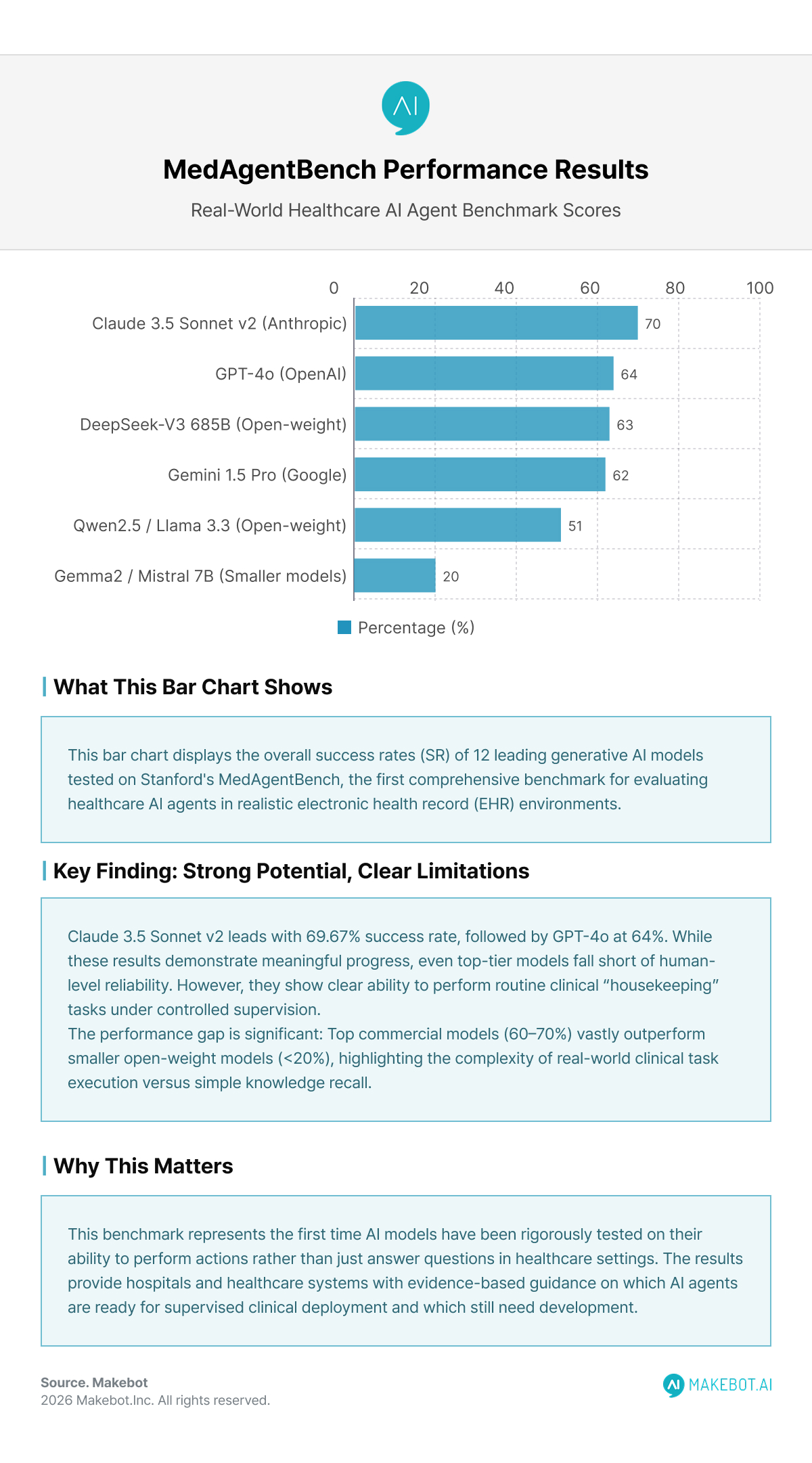
What the Results Reveal: Strong Potential, Clear Limitations
A dozen leading Generative AI models were tested. The results show meaningful but uneven progress:
Overall Success Rates (SR)
- Claude 3.5 Sonnet v2 — 69.67%
- GPT-4o — 64.00%
- DeepSeek-V3 (685B) — 62.67%
- Gemini-1.5 Pro — 62.00%
- Open-weight models (Qwen2.5, Llama 3.3) — 46–51%
- Smaller models (Gemma2, Mistral 7B) — <20%
Even top-tier models fall short of human-level reliability, but they demonstrate clear ability to perform routine clinical “housekeeping” tasks under controlled supervision.
Common Failure Modes
Stanford researchers identified two dominant error patterns:
- Instruction adherence failures
- Invalid FHIR API calls
- Incorrect JSON structure
- Misinterpreting physician instructions
- Output mismatch
- Producing narrative explanations instead of structured values
- Missing required fields or metadata
These errors highlight the importance of workflow reliability, interoperability, and safety constraints, which traditional chat benchmarks cannot measure.
Why This Benchmark Is a Turning Point for AI in Healthcare
1. It Shifts AI Evaluation from Knowledge to Action
- Previous benchmarks answered: “Does the model know medicine?”
- MedAgentBench answers: “Can the model practice medicine safely under supervision?”
That shift is monumental. The entire future of autonomous or semi-autonomous clinical systems depends on proving safe action, not just smart conversation.
2. It Mirrors Regulatory and Industry Demands
As the FDA increases focus on “real-world performance” of AI-enabled medical devices, and healthcare systems adopt Responsible AI frameworks, Stanford’s benchmark fills a critical gap.
It provides:
- A reproducible evaluation system
- Clinically meaningful metrics
- Clear error categorization
- A shared foundation for model comparison
3. It Helps Clinicians Trust and Adopt Medical AI
Quotes from Stanford researchers emphasize a key message: These systems are not replacing clinicians—they are augmenting them.
Kameron Black notes: “AI won’t replace doctors anytime soon. It’s more likely to augment our clinical workforce.”
With healthcare facing a projected global shortage of more than 10 million workers by 2030, scalable assistance for documentation, EHR navigation, and administrative tasks could meaningfully reduce burnout and improve patient care.
Deloitte: 75% of Healthcare Leaders Are Scaling Generative AI to Transform Care and Operations. Read here!
Clinical Impact: Where Healthcare AI Agents Can Help First
Based on benchmark performance and observed error patterns, the earliest safe applications of Healthcare AI Agents will focus on:
1. Administrative and EHR Housekeeping
- Chart summarization
- Lab trend retrieval
- Medication list updates
- Structured documentation
These tasks require accuracy but follow predictable workflows.
2. Low-Risk Order Assistance
Under human-in-the-loop review, AI agents can draft:
- Lab test orders
- Imaging recommendations
- Medication refills
Clinicians retain approval authority, ensuring safety.
3. Care Coordination and Patient Engagement
As seen in Stanford Health Care’s collaboration with Qualtrics, Generative AI agents can:
- Flag missed appointments
- Trigger follow-up actions
- Resolve discharge bottlenecks
- Identify language or resource barriers
These tasks reduce friction without direct medical risk.
The Road Ahead: From Benchmark to Real-World Pilots
Stanford researchers emphasize that performance is improving rapidly. Newer LLM versions show significant gains when tuned for observed error patterns.
Key requirements for safe deployment include:
- Guardrails (timeouts, role limitations, formulary constraints)
- Transparent audit logs
- Human approval for high-risk actions
- Continuous post-deployment monitoring
- Governance committees overseeing model updates
With these in place, Black believes pilot deployments are closer than most expect. “With deliberate design, safety, structure, and consent, it will be feasible to move these tools from research prototypes into real-world pilots.”
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy. More here!
Conclusion
MedAgentBench marks a foundational moment for the future of AI in Healthcare. By setting a clear, clinically grounded standard for evaluating action-taking systems, Stanford University has accelerated the industry’s path toward trustworthy, operational Medical AI.
The message is not that AI is ready to replace clinical judgment—far from it. Instead, Stanford’s benchmark reveals a more realistic and exciting trajectory: AI agents becoming reliable teammates that help clinicians reclaim time, reduce burnout, and focus on what matters most—patient care.
As hospitals, regulators, and AI developers align around standards like MedAgentBench, the healthcare ecosystem gains exactly what it needs: clarity, transparency, and a measurable roadmap for safe, responsible adoption.
The race ahead is no longer about building the smartest model—but the safest, most reliable, and clinically effective one.
Makebot: Bringing Safe, Clinically Aligned AI to Healthcare
This is where Makebot bridges the gap—delivering enterprise-grade, healthcare-specific AI agents designed to meet the same real-world performance standards highlighted by Stanford’s MedAgentBench. Built with strict guardrails, transparent auditability, and domain-tuned reasoning, Makebot’s solutions ensure that hospitals can adopt AI safely, reliably, and in alignment with clinical workflows.
With proven deployments in leading institutions and technologies like HybridRAG achieving global benchmarks in accuracy and cost efficiency, Makebot enables health systems to move from experimentation to real-world impact. From automated chart summaries to patient-facing agents and clinical decision support, Makebot provides the structure and stability required for responsible AI adoption at scale.
👉 www.makebot.ai | 📩 b2b@makebot.ai
































.jpg)

.png)





















































_2.png)








