


Large language models have reached a level of fluency and reasoning capability that makes them appear almost self-sufficient. With billions—or even trillions—of parameters trained on massive corpora, modern Large Language Models can write code, summarize research, reason through problems, and hold nuanced conversations. This raises a fundamental architectural question in modern AI Development:
Can an LLM work effectively without Retrieval Augmented Generation (RAG)?
The short answer is yes—but with important caveats. The long answer reveals why RAG has become a default pattern for production-grade AI systems.
Are Large Language Models (LLMs) the Future of AI? Read more here!
Glossary of Key Technical Terms
Transformer Architecture. A neural network design based on self-attention mechanisms that allows Large Language Models to model long-range token dependencies efficiently and in parallel.
Training Cutoff. The fixed point in time after which an LLM has no knowledge, due to training on static datasets rather than live information.
Hallucination. A failure mode where an LLM generates fluent but factually incorrect outputs when required information is missing or outside its training distribution.
Context Window. The maximum number of tokens an LLM can process at once, limiting how much information can be considered during inference.
Vector Database. A storage system used in Retrieval Augmented Generation that indexes embeddings to enable semantic similarity search over large, unstructured datasets.

Understanding the Standalone LLM
At its core, an LLM is a probabilistic sequence model trained to predict the next token given prior context. Architecturally, most state-of-the-art models rely on transformer-based attention mechanisms that encode statistical relationships across vast textual datasets.
When deployed without RAG, an LLM operates in a closed-world setting:
- Its knowledge is entirely embedded in model parameters
- That knowledge is static, bounded by the training cutoff
- It has no direct access to external, proprietary, or real-time data
This design works remarkably well for:
- General knowledge queries
- Language transformation tasks (summarization, rewriting, translation)
- Creative generation
- Reasoning over information already present in the prompt
In these scenarios, retrieval adds little marginal value and may even introduce unnecessary latency.
Where Standalone Large Language Models Excel
LLMs without retrieval mechanisms remain highly effective in several well-defined contexts:
1. General-Purpose Reasoning and Language Tasks
Tasks such as grammar correction, ideation, content drafting, or abstract reasoning rely more on linguistic competence than factual precision. Here, standalone LLMs perform near optimally.
2. Stable Knowledge Domains
If the domain knowledge changes slowly (e.g., classical mathematics, basic programming concepts), the lack of real-time access is not a major limitation.
3. Low-Latency or Edge Deployments
In constrained environments, removing retrieval layers reduces system complexity, inference latency, and operational cost.
In other words, LLMs can function independently when freshness, verifiability, and domain specificity are not mission-critical
The Structural Limits of Non-RAG Systems
Despite their strengths, standalone LLMs exhibit well-documented limitations that become critical in production settings.
Static Knowledge and the Freshness Problem
Retraining large models is expensive, slow, and operationally complex. As a result, an LLM’s understanding of the world becomes outdated almost immediately after deployment.
Hallucination Risk
When asked about information outside their training distribution, LLMs tend to extrapolate confidently. This leads to hallucinations—plausible but incorrect outputs—particularly in technical, legal, or medical contexts.
Context Window Inefficiency
Passing large documents directly into prompts is costly and constrained by token limits. Without retrieval, developers often resort to truncation or oversimplification, reducing answer quality.
These issues are not theoretical. They directly affect trust, safety, and adoption in enterprise AI systems.
What Retrieval Augmented Generation Changes
Retrieval Augmented Generation introduces an architectural shift rather than a model upgrade.
Instead of forcing the LLM to “know everything,” RAG systems:
- Retrieve relevant documents from external sources (vector databases, APIs, internal repositories)
- Inject only the most relevant context into the prompt
- Ask the LLM to generate responses grounded in retrieved evidence
This transforms the LLM from a closed-world generator into an open-book reasoner.
Empirically, RAG-based systems demonstrate:
- Higher factual accuracy in knowledge-intensive tasks
- Reduced hallucination rates
- Faster knowledge updates without retraining
- Better alignment with proprietary or regulated data sources
How is RAG used in Generative AI. More here!
LLM vs RAG: Architectural Trade-Offs
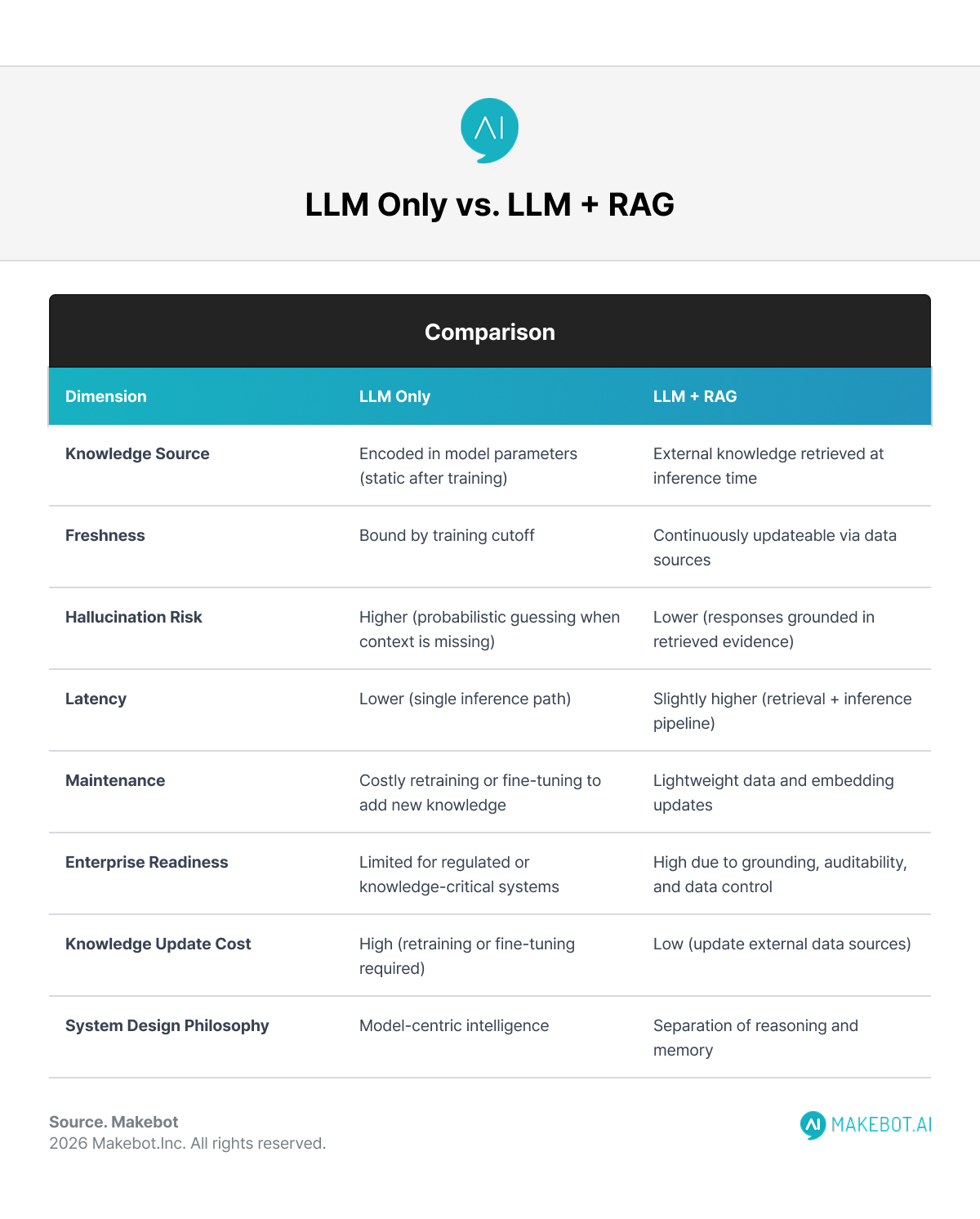
When Does It Make Sense to Skip RAG?
Despite its benefits, RAG is not mandatory in every system. You may reasonably avoid it when:
- The task is language-centric rather than knowledge-centric
- The domain is generic and stable
- Low latency or simplicity is prioritized over factual grounding
- The application is exploratory, creative, or non-critical
In these cases, adding RAG may increase complexity without proportional returns.
When RAG Becomes Non-Negotiable
RAG is effectively required when:
- Answers must be verifiable and up to date
- The system relies on proprietary or internal data
- Regulatory, legal, or clinical accuracy matters
- Users expect source-grounded responses
This is why RAG has become the default architecture for enterprise search, internal copilots, compliance assistants, and knowledge-based chatbots.
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy. More here!
Final Perspective
So—can LLMs work without RAG?
Yes. And they already do, at a massive scale. But the more important question in modern AI Development is not can they, but should they.
Standalone Large Language Models offer fluency, reasoning, and creativity. Retrieval Augmented Generation adds grounding, accountability, and adaptability. The most effective systems are designed by understanding this boundary—not by blindly maximizing architecture complexity.
In practice, high-performing AI systems are not defined by whether they use RAG, but by whether their architecture matches the epistemic demands of the task.
That distinction is where real AI engineering begins.
In practice, effective AI Development depends less on choosing between an LLM or RAG and more on aligning system architecture with real knowledge demands. This is where Makebot’s HybridRAG framework fits naturally—combining Large Language Models with Retrieval Augmented Generation in a way that balances grounding, latency, and cost for enterprise use cases. Validated in production and presented at SIGIR 2025, HybridRAG reflects the article’s core takeaway: strong AI systems are built on deliberate architectural trade-offs, not one-size-fits-all solutions.
👉 www.makebot.ai | 📩 b2b@makebot.ai
































.jpg)

.png)





















































_2.png)








