
How Enterprise Hospitals Are Combining RAG with GPT-5 for Safer Healthcare AI Systems
RAG cuts clinical AI hallucinations 40%+ — how enterprise hospitals deploy GPT-5 safely at scale.


Introduction
Clinical AI is no longer a theoretical horizon — it is an operational reality reshaping how enterprise hospitals diagnose, document, and deliver care. But as generative AI capabilities expand, so do the risks. Models trained on broad, static datasets are prone to hallucination, factual drift, and a dangerous inability to access the real-time, patient-specific context that clinical decisions demand.
This is where the convergence of Retrieval-Augmented Generation (RAG) and GPT-5 healthcare AI becomes strategically significant. Rather than deploying raw generative models and hoping for accuracy, leading hospital systems are constructing hybrid architectures where RAG with GPT-5 works in tandem: RAG pipelines pull verified clinical knowledge — from EHR records, drug databases, treatment guidelines, and peer-reviewed literature — and feed it directly into GPT-5's reasoning layer before any output is generated.
The result is a fundamentally safer class of generative AI in healthcare: one that combines the deep reasoning capabilities of state-of-the-art large language models with the controlled, auditable precision of domain-grounded retrieval systems. This article examines how enterprise hospitals are building these systems, what outcomes they're achieving, and what governance and technical structures distinguish those leading the transformation from those still struggling to move past the proof-of-concept stage.
OpenAI Releases GPT-5.5 Instant: A New Default Model for ChatGPT. Explore the latest insights here!
Why General-Purpose LLMs Fall Short in Clinical Environments
The clinical environment is uniquely unforgiving. A misidentified drug interaction, an outdated treatment protocol, or a hallucinated lab reference range can have consequences that extend far beyond a business error. Yet when general-purpose large language models are deployed without retrieval grounding, these failure modes are predictably common.
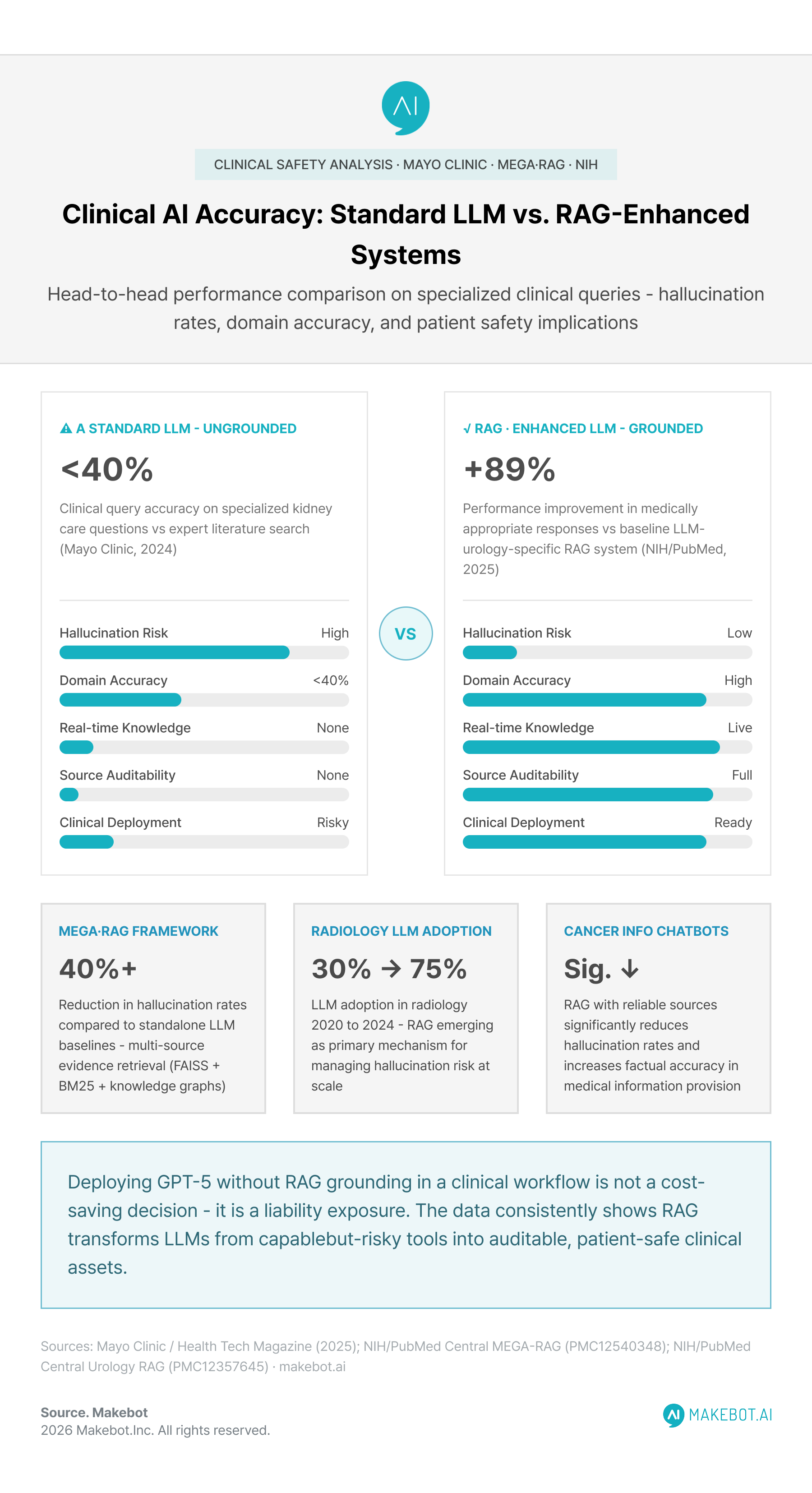
A 2024 Mayo Clinic study found accuracy rates of less than 40% for prompts on leading commercial AI platforms compared with in-depth literature searches for questions on kidney care — a finding that applies broadly to any high-stakes clinical domain. The authors concluded that in critical healthcare decision-making, the impact of such inaccuracies is considerably heightened, highlighting the need for models that are more reliable and precise.
The underlying technical problem is structural. Standard LLMs generate responses from learned statistical patterns across their training corpus. In fast-evolving clinical fields, that corpus is inherently outdated the moment training ends. Emerging drug approvals, revised clinical guidelines, patient-specific contraindications, and real-time lab data simply don't exist in a model's parametric memory — regardless of how powerful that model is.
GPT-5 raises the capability ceiling substantially. GPT-5 represents a significant leap in intelligence over previous models, featuring state-of-the-art performance across coding, math, writing, health, and visual perception. But raw intelligence without grounded, verified retrieval is insufficient for clinical decision support. The hospitals building the most robust enterprise healthcare AI architectures understand this distinction clearly — and are investing accordingly.
LLMs as Clinical Co-Pilots (Not Decision Makers). Read the expert analysis here!
What RAG Actually Does in a Hospital AI System
Retrieval-Augmented Generation is not a simple plugin for a language model. In clinical deployments, it constitutes a multi-stage information pipeline that runs before and around the generative model, not merely alongside it.
When a clinician queries a RAG healthcare system, the architecture executes in sequence:
- The query is vectorized and matched against curated knowledge bases — which may include hospital formularies, EHR patient records, clinical guidelines (e.g., ADA Standards, ACC/AHA protocols), and indexed medical literature.
- Retrieved document chunks are ranked by semantic relevance and passed to the generation layer as grounded context.
- GPT-5 generates a response conditioned on that retrieved evidence, with its parametric knowledge acting as a secondary, supplementary layer rather than the primary source.
- In more advanced deployments, attribution modules trace each statement in the output back to a specific source document, enabling auditable, traceable AI responses.
RAG offers a novel framework that connects LLMs with external knowledge, enabling them to access information beyond their training data — directly addressing the hallucination and outdated information limitations that restrict generative AI's full potential within healthcare settings.
The clinical implications are significant. Rather than a model "recalling" a treatment protocol it was trained on months ago, a RAG-grounded system actively retrieves the current, authoritative version of that protocol — from the institution's own clinical knowledge base — at the moment the query is made.
Research confirms the safety gains are measurable. The MEGA-RAG framework, which integrates multi-source evidence retrieval including dense retrieval via FAISS, keyword-based retrieval via BM25, and biomedical knowledge graphs, achieved a reduction in hallucination rates by over 40% compared to standalone LLM baselines. In a domain where hallucinations can directly affect patient safety, a 40%-plus reduction is not an incremental improvement — it is a clinical-grade advancement.
Reducing Hallucinations in Clinical LLMs Using Retrieval Augmented Generation. Discover what’s next here!
GPT-5's Role in Advancing Clinical Reasoning
GPT-5 introduces capabilities that make it qualitatively more suitable for AI clinical decision support than its predecessors. Beyond raw benchmark performance, three characteristics are particularly relevant to enterprise hospital deployments.

Reasoning depth under uncertainty. GPT-5 Pro achieved 88.4% on the GPQA Diamond benchmark (without tools) — the score belongs to the extended-reasoning Pro variant, not the standard GPT-5 model, which scores 77.8% (or 85.7% with thinking enabled). This level of scientific reasoning, even at the standard tier, enables advanced clinical decision support. In clinical contexts, this translates to the ability to reason through differential diagnoses, weigh drug interactions against patient history, and generate structured clinical rationales — not just pattern-matched responses.
Unified multimodal architecture. Unlike earlier GPT generations that required separate models for different modalities, GPT-5's unified architecture processes text, images, and structured data within a single inference pipeline. For hospital systems combining radiology reports, EHR notes, and lab values in a single clinical query, this architectural consolidation reduces both integration complexity and the risk of context loss across model handoffs.
Healthcare-specific evaluation and deployment infrastructure. OpenAI has partnered with over 262 licensed physicians across 60 countries to evaluate GPT-5.2 model performance using real clinical scenarios — with that group reviewing over 600,000 model outputs across 30 areas of focus. OpenAI for Healthcare products (ChatGPT for Healthcare and the OpenAI API for Healthcare) are powered by GPT-5.2 models with HIPAA-compliant BAA eligibility for enterprise deployments. This institutional infrastructure is a meaningful signal that enterprise-grade GPT-5 healthcare AI is no longer a research prototype — it is an infrastructure decision.
When GPT-5's reasoning is coupled with RAG-grounded retrieval, the combination addresses the two most critical failure modes in healthcare AI simultaneously: factual inaccuracy and contextual irrelevance.
Can LLMs Work Without RAG? Explore the future of AI here!
Enterprise Deployment Patterns: What High-Performing Hospital Systems Are Building
The gap between hospitals achieving meaningful clinical AI ROI and those still cycling through inconclusive pilots is not primarily a technology gap — it is an architectural and governance gap. Leading enterprise systems share a recognizable deployment pattern.
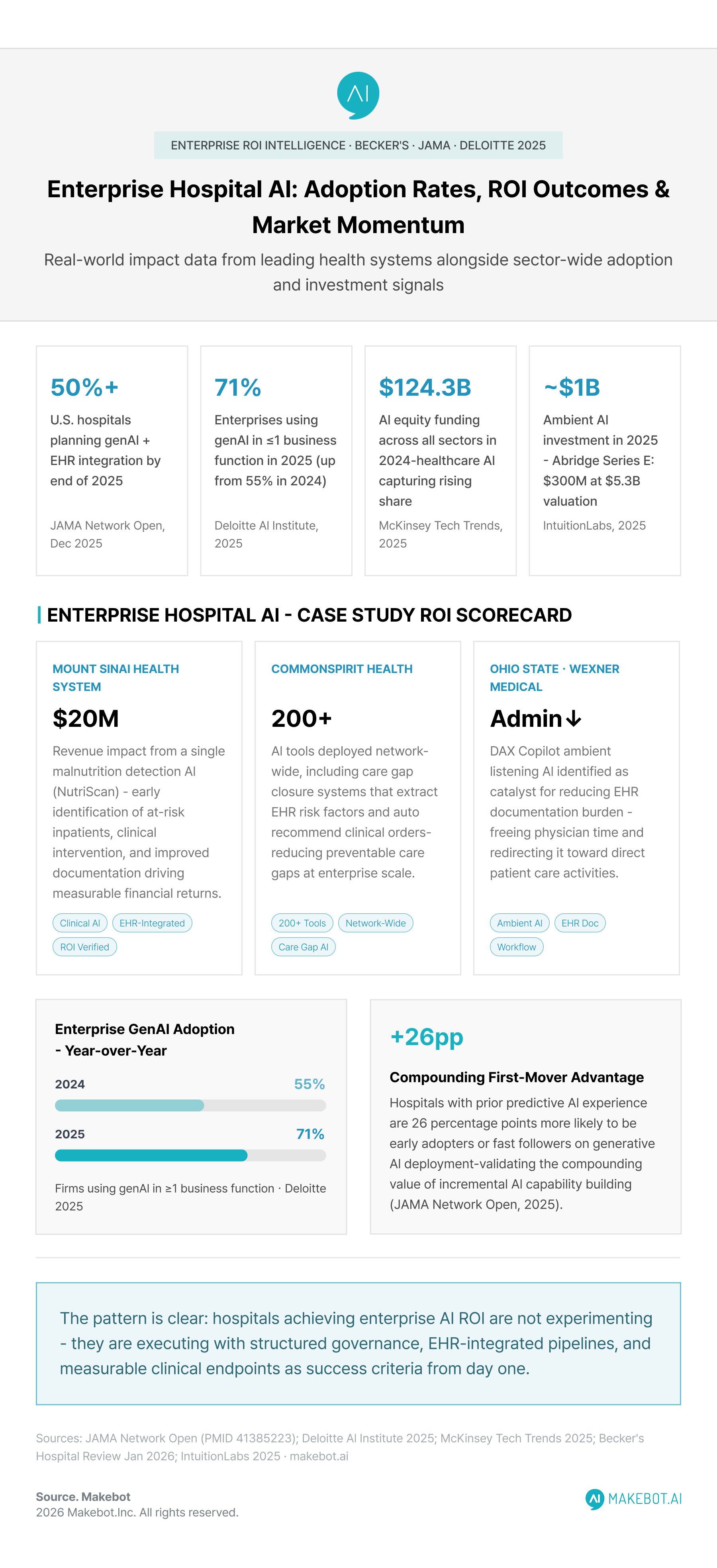
CommonSpirit Health has deployed over 200 AI tools across its network, including an AI-powered care gap closure system that uses AI to extract risk factors from EHR data and recommend appropriate clinical orders. Mount Sinai Health System reported that an internally developed malnutrition detection AI — which identifies inpatients at risk and prioritizes them for clinical nutrition team assessment — generated approximately $20 million in revenue impact through early detection, intervention, and documentation.
Ohio State University Wexner Medical Center identified ambient listening AI (DAX Copilot) as a catalyst for reducing administrative burden on clinicians — freeing physician time that was previously absorbed by EHR documentation and redirecting it toward patient care.
These deployments share several structural features:
- EHR integration maturity — retrieval pipelines are connected to live Epic or Oracle Health EHR data streams, enabling real-time contextual grounding rather than static database queries.
- Human-in-the-loop review — GPT-5 outputs feed into clinical workflows as decision support, not autonomous action, preserving clinician authority and accountability.
- Outcome tracking from day one — ROI is measured against clinical endpoints (detection rates, readmissions, documentation time) not just system utilization metrics.
A 2025 JAMA Network Open survey study of U.S. nonfederal acute care hospitals found that more than half of U.S. hospitals reported they would likely implement generative AI integrated with EHR systems by the end of 2025. Hospitals with prior experience in predictive AI were 26 percentage points more likely to be early adopters or fast followers — underscoring the compounding advantage of building AI organizational capability incrementally.
OpenAI Report Reveals Accelerating Enterprise AI Adoption in Healthcare. See how enterprises are transforming here!
The Hallucination Problem
In enterprise software contexts, a hallucinated output is an embarrassment. In a clinical context, it is a patient safety event. This distinction has driven the rapid adoption of RAG healthcare systems in hospital environments where healthcare AI safety is a regulatory, legal, and ethical obligation — not simply a product quality goal.
Evidence from 2024 to 2025 demonstrates that RAG strategies enhance diagnostic accuracy by grounding responses in verified medical literature, while multi-agent frameworks enable cross-validation through role-based specialization and systematic workflow orchestration. In radiology specifically, LLM adoption has accelerated from 30% in 2020 to over 75% in 2024 — with RAG emerging as a primary mechanism for managing hallucination risk at scale.
Research on cancer information chatbots provides one of the clearest quantified demonstrations: Using RAG with reliable information sources significantly reduces the hallucination rate of generative AI chatbots and increases factual accuracy in medical information provision. The same principle scales to diagnostic support, treatment planning tools, and clinical documentation systems.
A urology-focused RAG-enhanced clinical system achieved a 89% performance improvement in generating medically appropriate answers compared to baseline LLMs, along with improvements in hallucination mitigation and domain relevance. RAG-enhanced systems show strong potential for clinical use by producing trustworthy, context-aware responses, addressing key challenges in medical AI including hallucination mitigation and domain relevance.
The implication for hospital technology leaders is clear: deploying GPT-5 without RAG grounding in a clinical workflow is not a cost-saving decision — it is a liability exposure.
Accenture and OpenAI expand their Enterprise AI partnership, accelerating global AI innovation. Learn how industry leaders are adapting here!
AI Governance in Healthcare: The Architecture Behind Safe Scaling
Technology architecture alone does not explain why some hospital systems scale AI effectively while others stall. AI governance in healthcare — the organizational structures, evaluation processes, and oversight mechanisms that surround AI deployment — is the decisive variable. And at the center of every governance framework worth building is a clear, operational commitment to healthcare AI safety: not as a compliance checkbox, but as a design principle embedded from the first architecture decision.
McKinsey's 2025 healthcare technology analysis notes that public confidence in AI providers has slipped from 61% in 2019 to just 53% in 2024, and that in healthcare, this skepticism could hinder adoption of AI-powered clinical tools unless organizations demonstrate explainability, fairness, and transparency — while companies prioritizing digital trust outperform peers financially.
High-performing hospital AI programs build governance frameworks that address four dimensions simultaneously:
- Clinical validation before deployment — requiring accuracy, bias, and post-deployment evaluations before any AI tool enters a clinical workflow.
- Explainability requirements — mandating that vendor systems provide model cards or interpretability features, enabling clinicians to understand and challenge AI outputs.
- Ongoing monitoring infrastructure — real-time surveillance for model performance drift, particularly in RAG pipelines where the quality of retrieved context directly affects output reliability.
- Interdisciplinary oversight committees — clinicians, data scientists, compliance officers, and ethicists jointly reviewing AI tools, not just IT departments acting in isolation.
Accenture's Tech Vision 2025 emphasizes that as AI transitions from automation enabler to autonomous partner in healthcare delivery, organizations must develop a comprehensive digital core that combines knowledge graphs, fine-tuned models, orchestrating agents, and enterprise-grade architecture. Hospitals that invest in this integrated infrastructure — rather than point solutions — are building the foundation for durable, scalable hospital AI systems.
Key Healthcare AI Trends Shaping Innovation in 2026. Explore the data and findings here!
Challenges That Enterprise Hospitals Must Navigate
Even well-resourced hospital systems face significant friction when scaling RAG-based generative AI in healthcare pipelines. Understanding these friction points is essential for realistic deployment planning.
EHR data quality and interoperability. RAG systems are only as reliable as the knowledge bases they retrieve from. Many hospitals' EHR data contains errors, inconsistent coding, and missing fields. AI tools trained or calibrated on one institution's EHR frequently underperform when deployed elsewhere — a portability challenge that HL7 FHIR standardization is beginning to address, but has not yet resolved at scale.
Regulatory uncertainty. The FDA's 2025 draft guidance proposes a risk-based framework for AI in pharmaceutical and clinical contexts, and the broader regulatory landscape for continuously learning AI systems — models that update based on deployment feedback — remains in active development. Hospitals building adaptive RAG pipelines must design for regulatory review cycles that may require re-validation after significant model or retrieval updates.
Clinician trust and adoption rates. Technical accuracy does not automatically translate to clinical adoption. Trials at institutions like Atrium Health found that while AI scribe tools showed measurable efficiency gains for some clinicians, approximately 50% of users saw no time-saving benefit — and some preferred their own documentation workflows. Tailoring AI deployments to individual clinical workflows, providing structured training, and managing adoption expectations are organizational competencies that technology investment alone cannot substitute.
Cost-to-ROI timing. Hospital administrators consistently ask how long positive ROI will take to materialize from AI investments. The evidence emerging in 2025 — Mount Sinai's $20M malnutrition AI, CommonSpirit's care gap closure system — suggests meaningful ROI is achievable within the first 12 to 24 months of mature deployment, but only when governance structures and integration quality are in place from the outset.
Showcasing Korea’s AI Innovation: Makebot’s HybridRAG Framework Presented at SIGIR 2025 in Italy. Read here!
The Broader Market Signal: RAG and Healthcare AI Investment Momentum
The financial and institutional signals surrounding RAG healthcare systems and enterprise healthcare AI are unambiguous. The global Retrieval-Augmented Generation market was valued at USD 1.2 billion in 2024 and is projected to reach USD 11.0 billion by 2030, growing at a CAGR of 49.1%.
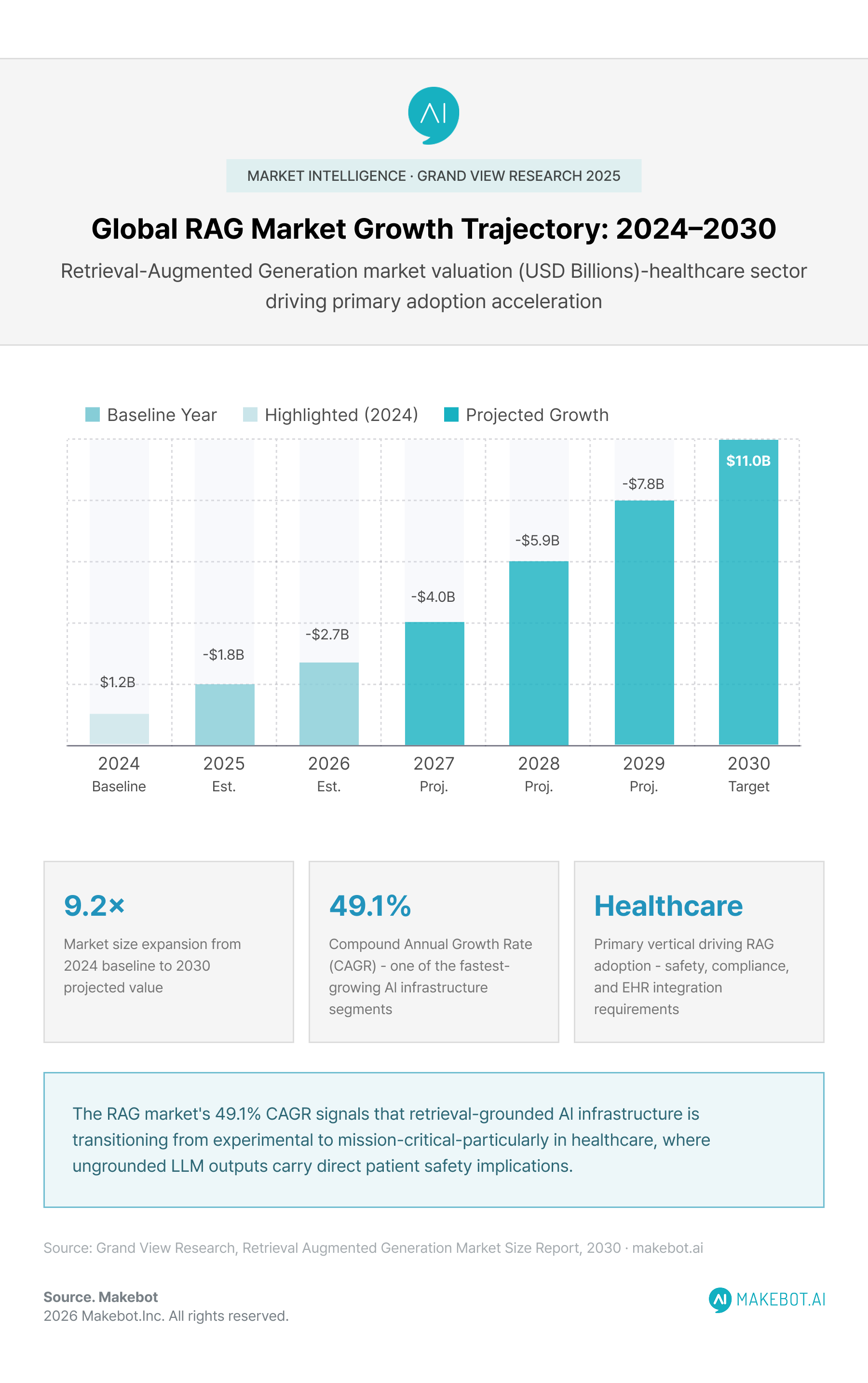
AI led all investment trends in 2024 with $124.3 billion in equity funding across sectors, and healthcare AI is commanding an increasing share of that capital. Ambient AI companies alone attracted nearly $1 billion in 2025 investment, with Abridge raising a $300 million Series E and reaching a $5.3 billion valuation — a clear indicator of institutional confidence in AI-integrated clinical workflows.
Deloitte's 2025 enterprise AI research reports that 71% of firms are using generative AI in one or more business functions, up from 55% in 2024, with healthcare representing one of the fastest-accelerating verticals. The convergence of GPT-5's clinical capabilities, RAG-grounded retrieval architecture, and enterprise EHR infrastructure is creating the conditions for healthcare AI to move decisively from departmental pilot to institution-wide transformation.
Conclusion
The convergence of Retrieval-Augmented Generation and GPT-5 healthcare AI represents the most structurally coherent approach yet developed for deploying powerful generative AI safely within enterprise clinical environments. RAG addresses what raw language model capability cannot: the need for real-time, institution-specific, auditable knowledge grounding. GPT-5 provides what earlier AI models lacked: reasoning depth sufficient to synthesize complex clinical contexts into actionable, medically coherent support.
But the hospitals achieving the clearest clinical and financial outcomes from these systems share something beyond technical sophistication. They have built the governance structures, integration pipelines, and organizational cultures that allow AI to function as a reliable clinical partner — rather than an unpredictable, ungoverned liability.
For healthcare technology leaders, the strategic question has shifted. It is no longer whether to deploy enterprise healthcare AI at scale — the market evidence, clinical outcomes data, and competitive pressures make inaction increasingly untenable. The question is whether organizations are building the architectural foundation — RAG with GPT-5 as the core retrieval-reasoning layer, EHR integration depth, and robust AI governance in healthcare — that will determine whether their AI investments deliver sustained patient and operational value over the next decade.
The institutions investing in that foundation today will define the standard of care that others eventually follow.

.jpg)



































.jpg)

.png)





















































_2.png)



